
ช่วงนี้บ้าเข้ายิมมาก ระหว่างพักร่างกายไม่รู้จะทำอะไร เลยไถ Youtube หาอะไรเรียนไปเรื่อย บังเอิญเจอคลิปเลคเชอร์ของอาจารย์ท่านหนึ่ง เป็นวิชา AI Engineer ของอาจารย์ Nutchanon Yongsatianchot เราเห็นว่าน่าสนใจเลยลองเข้าไปเรียนดู รอบแรกดูแบบข้ามๆก่อนกะถ้าไม่ชอบก็หาอย่างอื่นดูต่อ ปรากฏว่า เห้ยยยยย! ดี!!!!! เลยนั่งตั้งใจเรียน ตั้งใจจด อยู่จนยิมปิด ค่อยกลับบ้าน 55555
ก่อนที่สิ่งที่เรียนมาจะหายไปจากสมองเรา ขอเอาที่จดมาเขียนสรุปในสรุปอีกทีนึง เขียนรู้เรื่องบ้างไม่รู้เรื่องบ้าง ลองดู
ไม่กี่ปีก่อนหน้านี้ ยุคของซอฟแวร์ การเขียนโปรแกรม เรียกว่ายุค 1.0 จะเป็นแบบ code ล้วน โปรแกรมเมอร์ใช้ GitHub ในการแชร์ code ตัวเอง และเรียนรู้ code จากคนอื่น ในยุคนี้ฉันยังเป็น trade specialist ตัวน้อย ณ ธนาคารแห่งหนึ่ง ตอนนั้นยังไม่ก้าวเข้ามาสายงานนี้
ยุคต่อมาเป็นยุค 2.0 มี machine learning/ neural network ละ เอาดาต้ามาสอนโมเดล แล้วเอามา inference ต่อ platform ยอดฮิตของยุคนี้คือ HuggingFace (เอาจริง เราเพิ่งรู้จักHF เมื่อ 2–3 ปีมานี้นี่เอง โลกมันไปไวมากกกกเลยทุกคน)
ส่วนยุคตอนนี้คือ 3.0 ไม่เขียน model แล้ว แต่เป็น prompt model เราแอบดีใจนะ แบบบ เวลาของกรูวมาแล้ววว เพราะตอนนี้ programming language ที่ฮอตฮิตที่สุดคือ ภาษาอังกฤษ ซึ่งฉันถนัดมากนะ 5555 และ Large Language Models หรือ LLMs นั้นคือ the new computer แล้วจ้าาา
อ่ะ แล้วทีนี้ AI engineer ต่างกับ machine learning engineer ยังไงล่ะ
ในท่าปกติของการทำโมเดล machine learning เราจะก็ input data เข้าไป ให้โมเดลเรียนรู้ ออกมาเป็น product ตามโจทย์ที่ได้รับมอบหมายมาให้ทำ
role ของ data scientist/ machine learning engineer จะทรงนี้
Data → Model → Product
แต่ตอนนี้ role AI engineer จะต่างตรงที่ มี LLMs มันตัวเปิดจ้ะ คือซัด prompt เข้าไปให้มันเลย ถ้า prompt ดี ทำสำเร็จ แล้วได้ข้อมูลมา ก็เอาเข้าโมเดลเพื่อเทรน
Product → Data → Model

ประมาณนี้พอสังเคป ให้รู้เฉยๆว่าเออโลกมันเปลี่ยนไปและ เราเองก็ต้องปรับตัว(เยอะ)พอสมควร 5555
ต่อไปแล้ว LLMs คืออะไร เรารู้แล้วเนอะว่ามันย่อมากจาก Large Language Models แปลแบบซื่อๆคือก็คือ โมเดลภาษา (ที่มีมากกว่า 1 โมเดล เพราะเป็นพหูพจน์ 5555) ที่มีขนาดใหญ่มว้ากกกก โมเดลท่าปกติที่อาจจะมี parameter จำนวนหนึ่ง (หลักร้อย หลักพัน) แต่อินี่มีเยอะมาก หลักพันล้าน หมื่นล้านนน เป็นล้านเลยหรอเพ่!!!
ปกติที่เรียน machine learning ไอ้เจ้า multi layer perceptron มันจะมี input node → hidden layer → output layer
node ใน hidden layer ที่โดนชี้มามันก็จะมี w1 w2 … ไรงี้ แต่ของ LLMs คือ เยอะสลัดรัสเซียหลักพันล้าน งานนี้มี RAM ด้อง อธิบายไม่ถูก ดูรูปกันดีกว่า
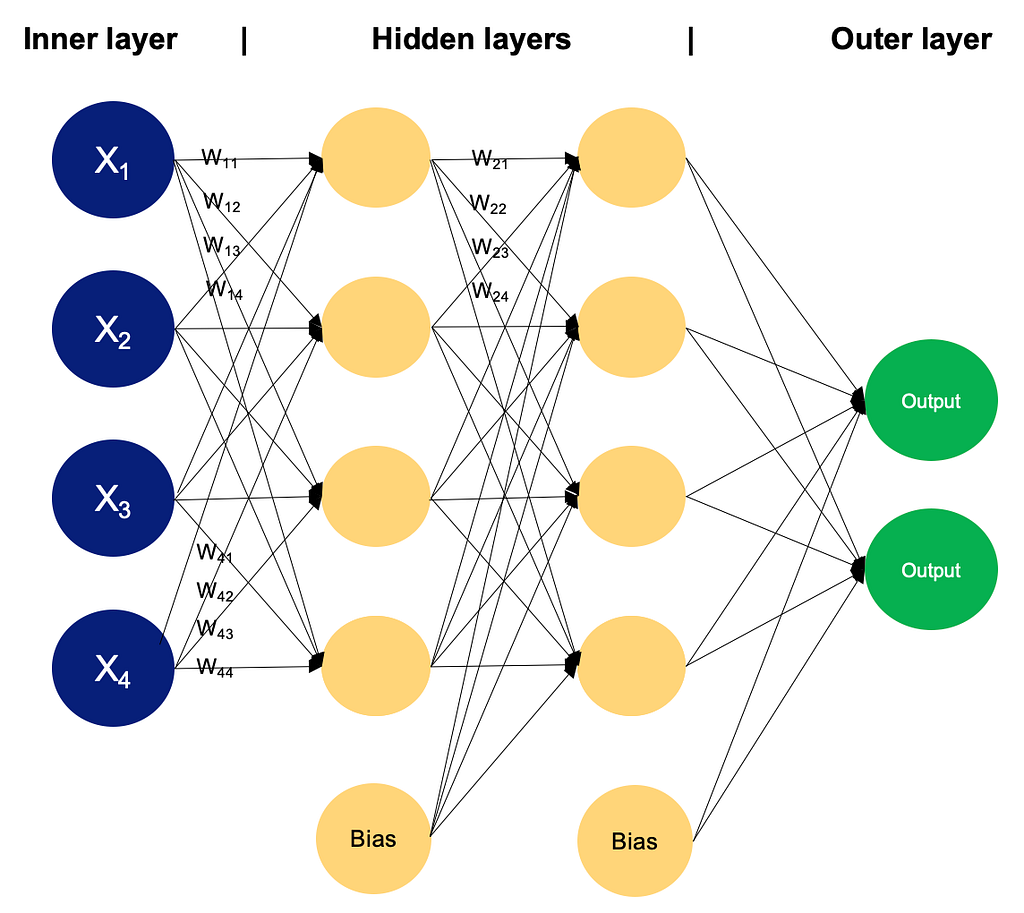
ฉันต้องตั้งสติก่อน และรับรู้ว่ามันคือโมเดลที่ทำหน้าที่ predict next word ทีละคำ แล้ว predict คำต่อๆไปเรื่อยๆ
This is a ______.
โมเดล หาความเป็นได้ของคำต่อไป given คำก่อนๆหน้านี้
P( next token | context)
เช่น P( book | This is a)
ซึ่งโมเดลมันใช้ probabilistic model ในการ “สุ่ม” คำต่อไปนะ มันถึงชอบตอบไม่เหมือนเดิม ซึ่งโมเดลในการจุ่มนี้เราก็สามารถใช้ API ได้จ้า
แล้วถ้ามันทำนายคำต่อไปได้เก่ง เราก็สามารถให้โมเดลช่วยเราตอบคำถาม แต่งเรื่อง นู่นนี่นั่นได้ (แบบมันเข้าใจด้วยนะ ไม่ใช่ทำนายมามั่วๆ) ฮั่นแน่!! มันคือ Generative AI ไงเล่าาาา
แล้วยังไงต่อล่ะ เราจะทำนายคำต่อไปยังไง จริงๆแล้วสิ่งที่ทำนายมันคือ token
token = subword หมายความว่าไม่ได้เอาคำมาทั้งก้อน
เช่น The runners were unstoppable! → [“The”, “runner”, “s”, “were”, “un”, “stop”, “pable”, “!”]
การ tokenize มันก็จะมี algorithm ที่ทำหน้าที่นี้ เช่น
Byte Pair Encoding (BPE): Alphabet ที่เกิดคู่กันบ่อยๆ เอามา merge รวมกันเป็น token ใหม่
การทำ tokenization คือ การแปลงคำเป็นตัวเลข (word to integer)ให้คอมพิวเตอร์เข้าใจนั่นเอง ซึ่งแต่ละสำนักของ Generative AI ก็จะมีการเทคนิคตัดคำที่ไม่เหมือนกัน และมีผลมากกับคำตอบที่มัน generate ออกมา (รวมถึงความเพี้ยนในคำตอบของมันด้วย)
สรุป language model คือการสุ่มทำนาย “token” ถัดไปด้วย probabilistic model พอได้ token ต่อไป ก็จะทำซ้ำไปเรื่อยๆ เรียกว่า Autoregressive
Autoregressive คือ การทำนาย token ต่อไปด้วย ข้อมูลก่อนหน้า แล้วต่อตูดไปเรื่อยๆ ดูตัวอย่างข้างล่างกันดีกว่า
Hello, how ____
P(“how” | “Hello”)
Hello, how are ____
P(“are” | “Hello how”)
Hello, how are you ____
P(“you” | “Hello how are”)
Hello how are you?
P(“<stop>” | “Hello how are you?”)
Hello how are you? <stop>
<stop> เป็น special token ให้มันหยุดทำ
อะไรประมาณนี้ เราจะเห็นว่า ประโยคมันยาวขึ้นเรื่อยๆ จากตอนแรกแค่ Hello คำเดียว เป็น Hello how are you และ คือ input มันยาวขึ้น เรียกว่า context window
context window คือ จำนวน token ที่โมเดลเอามาพิจารณาในครั้งเดียว
ChatGPT ดั้งเดิม context window มีขนาด 4k ส่วนเวอร์ชั่นใหม่ๆมีเป็นล้านแล้วเพร่! แต่โมเดลก็ไม่ได้จะไปสนใจ input หมดทุกตัวหรอกนะ เหมือนเวลาเราอ่านหนังสือ มันก็มีอ่านข้ามๆบ้าง 555
คุณ Andrej เขาบอกว่า LLMs มันเรียนมาจากภาษาคน มันเลยเหมือนมีจิตวิญญาณคนอยู่ รู้มาก ตอนอกหักเรานี่คุยกับ ChatGPT ฉ่ำ อารมณ์ปรึกษาพี่อ้อยพี่ฉอด 5555 แต่อาจจะต้องระวังเพราะบางทีมันก็ hallucinate หรือ หลอนยา ถ้าเราไปถามให้มันช่วยทำการบ้าน ก็อาจจะตอบอะไรมาผิดๆแต่มั่นหน้ามั่นโหนกได้ เอาเป็นว่า ระวัง
ปัจจุบัน LLMs ก็มีหลายเจ้า ชอบอันไหนก็ใช้อันนั้น ส่วนเราสายใช้ฟรี 5555
สำหรับวันนี้ขอสรุปไว้เท่านี้ก่อน เดี๋ยวมาเขียนสรุป Lecture 2 ต่อ เราใช้เศษเวลาหลังออกกำลังกายมาเขียนสรุป อาจจะไม่ได้อัปเดตไวมาก ใครที่หลงเข้ามา หวังว่าจะเป็นประโยชน์นะคะ ใช้ภาษาเขียนไม่ค่อยสลวยเท่าไหร่ ตั้งใจสรุปไว้ให้ตัวเองอ่านเองกันลืมเฉยๆ 5555
ถ้าชอบเรื่องประสบการณ์ในต่างประเทศ เราเคยเขียนไว้เหมือนกัน ลองมาแอบๆอ่านได้นะคะ ^_^
วันนี้ลาไปก่อนนะ บั้ยบายยยย