LLM สมองบิน EP.2 — LLMs เบสิค เด็กมัธยมอ่านก็เข้าใจ แต่เป็นเด็กห้องกิ้บเต๊ด
ครั้งก่อนเราพูดถึงเรื่องทั่วไปของ LLM ครั้งนี้มาสรุปเลคเชอร์อาจารย์นัทต่อกันด้วยเรื่องโมเดลเบื้องหลังของ LLM หลายๆคนน่าจะมาผ่านหูมาบ้าง นั่นก็คือโมเดล Transformer (มี mention อยู่ใน paper ชื่อ Attention is all you need) หน้าตาสถาปัตยกรรมมันก็เป็นแบบนี้
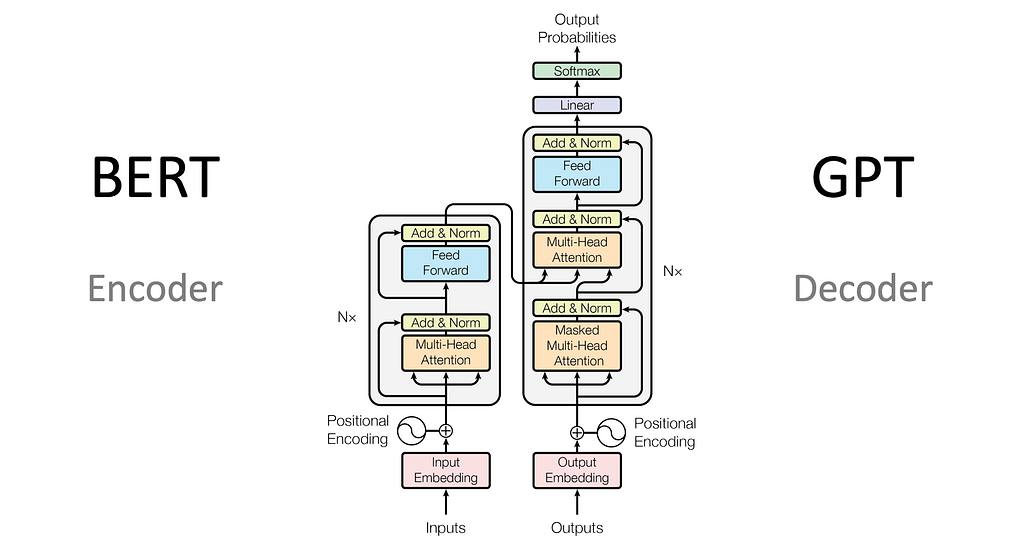
ซึ่ง LLM จะเอาแค่ฝั่ง Decoder มาใช้ อย่างที่พูดไปใน EP ที่แล้วคือ หน้าที่ของโมเดลคือ predict next token โดย feed sequence ของ token เข้าไป แล้วพ่นออกมาเป็น probability distribution ของทุก token
ในรูปดูฝั่ง Decoder จะเห็นว่า ตรง Outputs (จริงๆต้อง Inputs เพราะหยิบเอามาแค่ Decoder) จะเป็น input ที่ tokenize มาแล้ว เอาเข้า embedding ให้มันมี semantic information (ให้คำมีการเก็บความหมาย) จากนั้นก็เข้าไปส่วนสีเทาๆ คือเป็น layer ของ Transformers จะผ่าน Mutli Head Attention (เป็นตัวที่ทำให้เข้าใจความสัมพันธ์ของคำในประโยคได้) แล้วก็ผ่าน Feed forward ออกจากโซนเทา ก็จะพ่นออกมาเป็น Linear เป็น score ตามความยาว token แล้วก็ไปผ่าน softmax เพื่อ normalize คะแนนเต็ม 1 (ก็คือ probability)
เดี๋ยวมาดูแต่ละตัวกันว่ามันทำอะไร ทำยังไง
Word Embeddings คือการแปลง token เป็น vector ที่มีหลาย dimension แต่ละ dimension ก็จะเก็บ information ต่างกัน เป้าหมายของโมเดลคือให้คำที่มีความหมายใกล้เคียงกัน อยู่ใกล้กันใน vector space
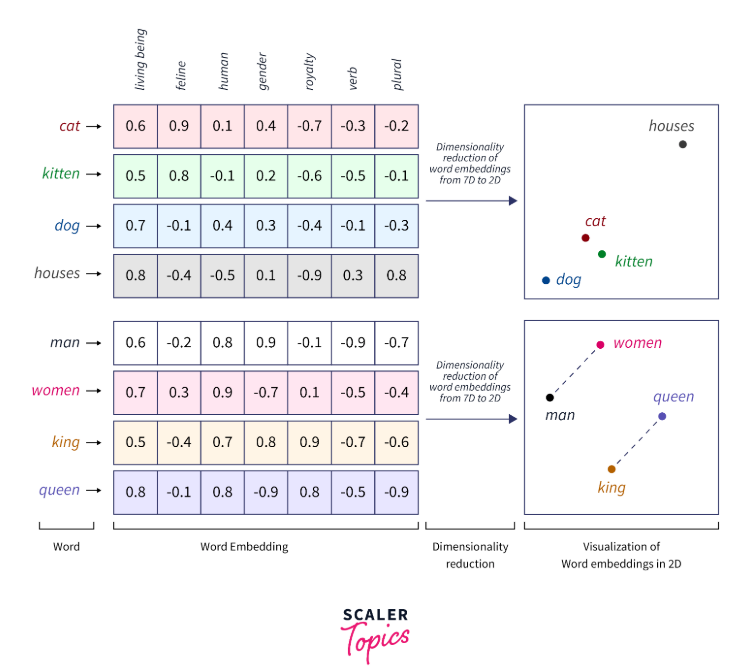
รูปข้างบนเขาทำดีแฮะ ขอยืมมาใช้หน่อย คำในฝั่งซ้ายมือ เอามาแปลงเป็น vector แล้วแต่ละกล่อง (dimension) ก็จะเก็บ feature ของคำนั้นๆไว้ แล้วอย่างที่บอกไปก่อนหน้านี้ว่า โมเดลต้องการหาคำที่ใกล้เคียงกันมาอยู่ใกล้ๆกัน วิธีหาคือจะหาโดย cosine similarity
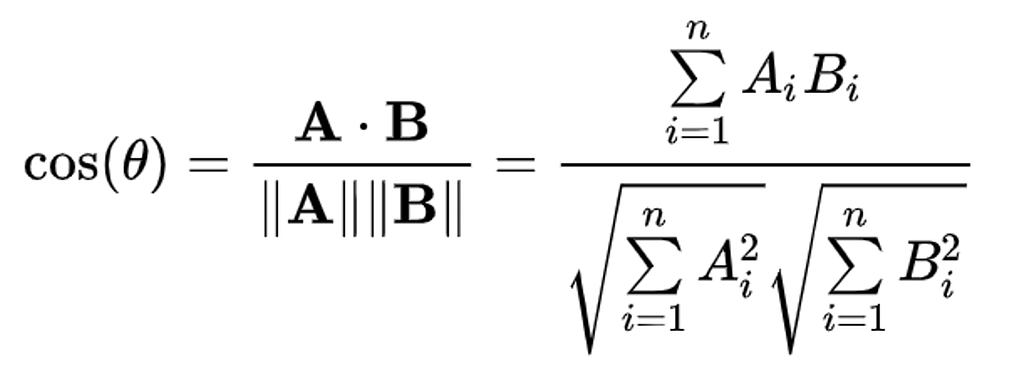
เห็นสูตรแล้วอาจจะตกใจ อ่านต่อไปจะเข้าใจ
อธิบายสูตร: เอา vector 2 vector หา dot product (เอาแต่ละกล่องของ vector คูณกัน แล้ว sum) หารด้วย normalise (ให้อยู่ระหว่าง -1 ถึง 1)
ค่ายิ่งมากยิ่งใกล้กันใน vector space ถ้างง เดี๋ยวดูตัวอย่างกัน
เราจะลองหา cosine similarity ของ man กับ woman แล้วก็ man กับ king ดูนะ
เริ่มจาก man กับ woman ก่อน
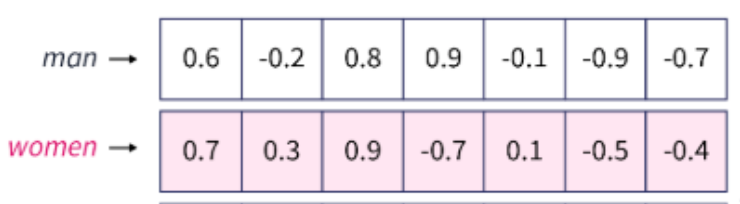
หา dot product (0.6*0.7) + (-0.2*0.3) + (0.8*0.9) + (0.9*-0.7) + (-0.1*0.1) + (-0.9*-0.5) + (-0.7*-0.4) = 1.17 ทดไว้ก่อน
ต่อไปมา normalize กัน ด้วย L2 regularization norm โดยการเอาค่าในแต่ละกล่องมายกกำลัง 2 แล้ว sum แล้วก็ครอบด้วย square root
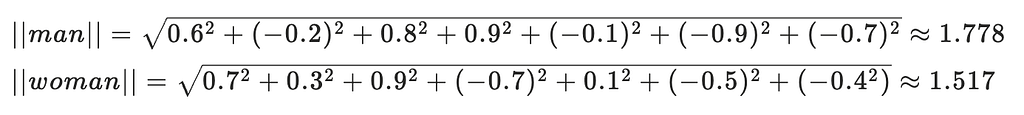
(หงุดหงิดจัง ทำไม Medium ไม่ support LaTeX อ่าาา นี่ใช้วิธีเขียนใน Notion แล้วแคปรูปมาแปะอีกที 555)
จากนั้นเอาที่ normalize มาคูณกัน 1.778 * 1.517 = 2.697
เอาที่ทดไว้ 1.17 หารด้วย 2.697
1.17 / 2.697 ≈ 0.434
cosine similarity ระหว่าง man กับ woman จะเป็น ≈ 0.434
ต่อไปลองระหว่าง man กับ king ดูบ้าง


ทำเหมือนเดิม เราขอเฉลยคำตอบเลยนะ cosine similar ระหว่าง man กับ king จะเป็น ≈ 0.824 ก็คือ man กับ king อยู่ใกล้กันใน vector space เหมือนกัน (เพราะค่ามันวิ่งเข้าหา 1)
นี่แหละการทำงานของโมเดล embedding
พักดมยาดมสักครู่…
Self Attention
หลังจากทำ embedding แล้วมันก็จะได้ semantic information หรือความหมายของคำมาแล้ว แต่บางคำก็ไม่ได้มีความหมายเดียว เช่นในเลคเชอร์อาจารย์นัทยกตัวอย่าง คำว่า Bank ที่มีความหมายว่า ธนาคาร และ ต้นน้ำ ซึ่งเราก็จะรู้ว่า ถ้ามี bank ในประโยคมันหมายถึง bank ไหนกันแน่ (พิจารณาจาก context)
ขออนุญาตแคปรูปจาก lecture อาจารย์มาเลยแล้วกันนะ เพราะเซิชหาแล้วมันเอามาอธิบายยาก
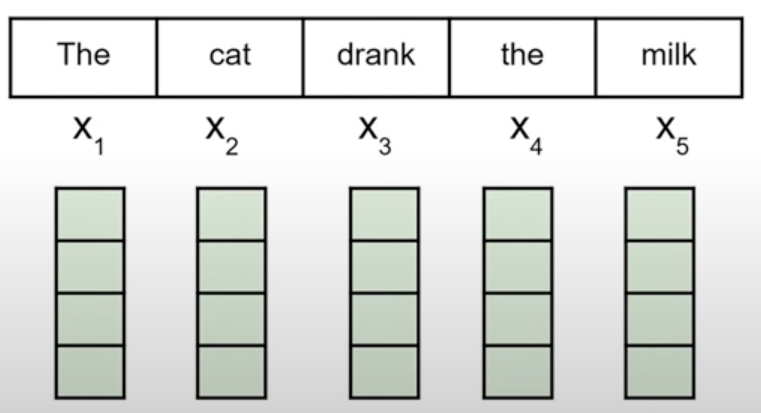
ในรูป คำว่า milk ก็อาจจะพิจารณาความเกี่ยวข้องกับคำว่า cat ที่เป็นประธาน และ drank ที่เป็นกริยาในประโยค
ไอกล่องเขียวๆข้างล่างที่เราเห็นก็คือ vector มาจากการทำ embedding ที่อธิบายไปแล้วก่อนหน้านี้ ซึ่งมันก็เก็บความหมายของคำไว้ด้วย
วิธีการหาว่า คำที่เราสนใจ เช่น milk ต้อง pay attention กับ คำอื่น เช่น The มากน้อยแค่ไหน จะใช้การหา Attention map
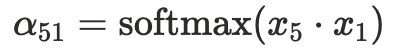
ในสมการนี้ก็คือเอา vector x5 กับ vector x1 มา dot product กัน แล้วครอบด้วย softmax อีกที ให้ค่าอยู่ระหว่าง 0 กะ 1
พอได้ค่าแล้วว่าควร pay attention มากแค่ไหน ก็เอาค่านั้นมา dot product กับ คำอื่นๆในประโยค แล้ว sum
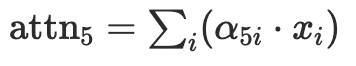
รวมกันเป็น 1 ก้อนที่ represent ความหมายของคำว่า milk (ถ้าความเข้าใจเรานะ คือเหมือนเป็น auxillary information เพิ่มเติม นอกหนือจาก semantic คือ relationship กับคำอื่นๆด้วย ทำให้โมเดลมันฉลาดขึ้น)
แต่มันยังไปได้อีกกกกกค่ะ คือที่อธิบายมาข้างบน มันก็ยังขาดความรู้ตรงที่ ควรจะ pay attention คำไหนมากน้อยยังไง ก็มีเลย parameter เพิ่มเติมมา คือ QKV (ทำไมเรานึกถึงร้านหมาล่าก็ไม่รู้ นั่นมัน CQK ป่ะ ชื่อคล้ายๆ ตอนเขียน หิว! 5555)
QKV มันย่อมาจาก Query Key Value
Query เป็น parameter เอามาคูณกะ vector ตัวที่สนใจ (milk)
Key คูณกะ vector ของคำอื่นในประโยค (The)
Value คูณกะ vector เพื่อ represent คำที่เราสนใจ (milk)
ดูสมการ น่าจะเก็ตมากกว่า จะเห็นว่าจะมี weight ของ QKV มาคูณกะ vector ด้วย
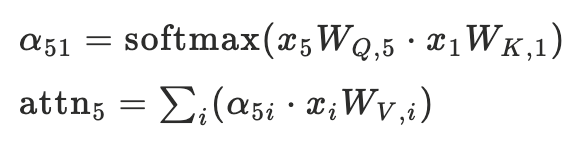
ดูรูปน่าจะเข้าใจมากขึ้น
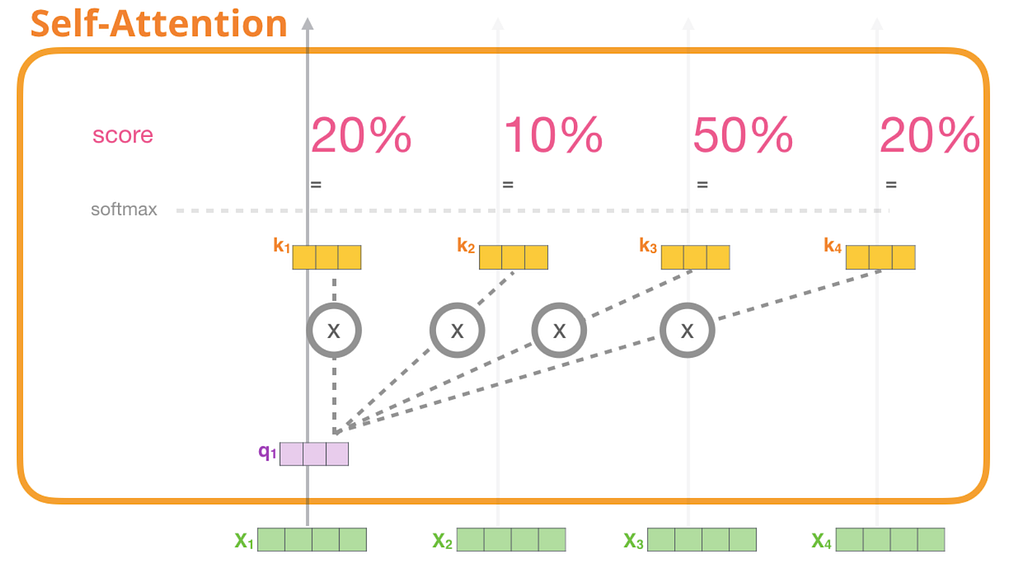
- เอา vector ของคำที่สนใจ คูณ กับ vector q จากนั้น เอาไปคูณกับ vector คำอื่น ที่ต่อกับ vector k ด้วย เสร็จแล้วครอบด้วย softmax จะได้ค่าออกมาเป็นระหว่าง 0–1 หรือ เป็น % ก็ได้แบบในรูปตัวอย่าง จากข้อนี้จะได้ ค่า attention score มา
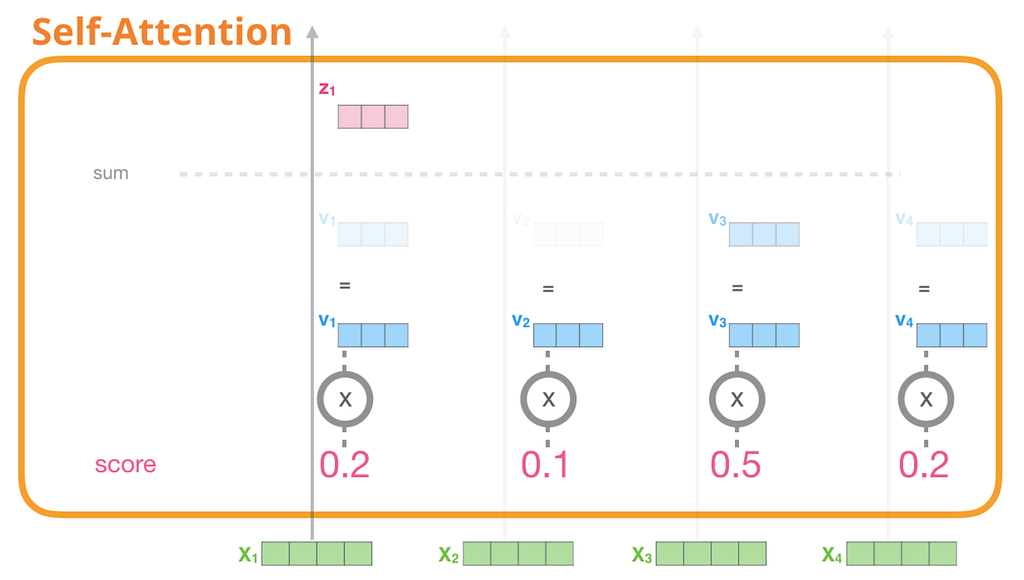
2. เอาค่า attention score จากข้อตะกี้ มาคูณกับ vector คำอื่นในประโยค คูณด้วย vector v ก็จะได้เป็น vector ที่เก็บ information ของความสัมพันธ์ระหว่างคำในประโยคออกมาด้วย เพื่อเอาไปเข้า Feed forward NN ต่อ
สามารถเข้าไปดูเพิ่มเติมในลิงค์ที่มาของรูปได้นะ เราว่าเขาอธิบายได้ดีมากๆเลยค่ะ
ในทางปฏิบัติจริงๆ มันจะทำพร้อมกัน เร็วมาก ก็เลยต้องใช้ GPU นะ ใครที่อยากรู้มันต่างกับ CPU ยังไง ทำไมการทำอะไรที่มัน parallel ต้องใช้ GPU แนะนำให้ดูอันนี้ค่ะ คลิปทำดีมาก ดูแล้วกระจ่างแจ่มแจ้ง
Feed Forward NN ขอไม่อธิบาย เพราะขี้เกียจเขียน มันไม่มีอะไรพิศดาร
ข้อดี ข้อเสียของโมเดล Transformer
ข้อดี
1. ประโยคยาวๆ (long term dependencies) ก็ไม่มีปัญหา ปกติโมเดลเก่าๆ อย่าง LSTM GRU ถ้าประโยคยาวๆมันจะได้หน้าลืมหลัง 555
2. run parallel ได้ ไม่ได้เป็น sequential แบบโมเดลสมัยก่อน (ใช้คำว่าสมัยก่อน แรงมากกก เพิ่งผ่านมาไม่กี่ปีเอง 5555) ทำได้เร็ว scale ได้
ข้อเสีย
1. O(n²) ช้า แพง เปลือง
2. Communication ใน GPU มี latency ในการส่งข้อมูลกัน (Distributed System)
3. Optimize hardware ได้ แต่คนจนล่ะมีสิทธิมั้ยคะ 555
DeepSeek V3
ต่อไปมาดู Transformer สมัยใหม่กัน (ณ วันนี้น่าจะโบราณแล้วมั้ง ไปเร็วจัด 5555)
ถ้าดูที่รูปแบบไวๆ จะเห็นว่า ก็คล้ายๆ Transformer อันเดิม คือมี Attention layer มี Feed Forword NN
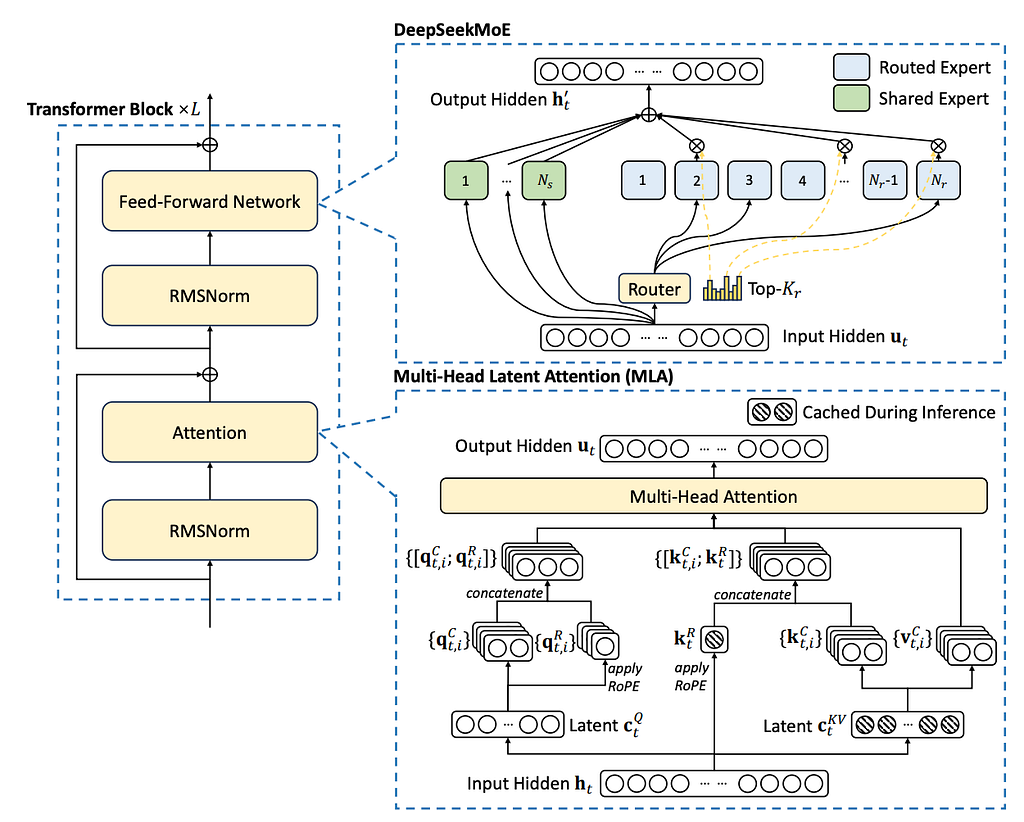
แต่สิ่งที่ต่างคือ ตรง Attention มีเพิ่ม Cached During Inference มา (ดูตรงกลมๆที่มีขีดๆข้างใน เหมือนขนมคุ้กกี้) หมายความว่ามันมีการ cache ไว้ เหมือนกักไว้ใช้ซ้ำ เพื่อให้ performance ของโมเดลมันดีขึ้น เลิกกั๊กแล้วรักก่อนนะเตง
ส่วน Feed forward layer มีตัว Router เพิ่มมา คือจะบาง node อาจจะให้อ่อมไปก่อน ไม่ต้องขยันมาก เลือกเฉพาะ node ที่จำเป็นให้ทำงาน ทำให้ลดเวลาการ inference แม้โมเดลจะมีขนาดใหญ่
ถ้าชอบอัปเดตข่าวสาร เราแนะนำไปดูต้นคลิปของเลคเชอร์อาจารย์เขาเลย ดีมากๆ เหมือนมีเพื่อนคนขยันมาสรุปให้ฟัง ฟังไปฟังมารู้สึกว่าตัวเองเป็นไดโนเสาร์ ล้าหลัง ชห 5555
LLM Pipeline

Source: https://github.com/giachat/State-of-GPT-2023
การเทรนโมเดล LLM จะแบ่งออกเป็น 2 ก้อน คือ pre-training กับ post-training
Pre-training คือการนำ data เยอะๆ มา train เพื่อทำ next word prediction (เคยเขียนอธิบายไว้แล้วอยู่ใน EP แรก)ได้ base model ขั้นตอนนี้เหมาะกับคนมีเงินเหลือเพราะใช้ทรัพยากรเยอะมากๆ แต่ base model มันก็ยังเอามาใช้ไม่ได้ เพราะมันถูกเทรนมาให้ทำนายคำต่อไปเท่านั้น จะให้มาตอบคำถาม ทำหน้าที่เป็น Assistant model ก็อาจจะยังน้าาา ต้องเอามา fine tune ในขั้นตอน post training ก่อน
Post-training คือการนำ base model มา fine tune โดยให้โมเดลมาเรียนรู้จาก response ที่ high quality สุดๆ (Supervised Fine-tuning) จนมันกลายร่างเป็น Instruct model ที่สามารถตอบคำถามตามที่เราต้องการได้ อารมณ์เหมือนพนักงาน call center ที่ถูกอบรมให้ตอบคำถามลูกค้ายังไงให้ลูกค้าพึงพอใจ แต่ก็ไม่ได้จะตอบให้พอใจได้ทุกคำถาม กรณีที่มีคำถามนอก scope งาน
ก็ยังมี Preference Fine-tuning ให้ตอบคำถามถูกใจกรรมการยิ่งขึ้น จะแบ่งออกเป็น reward model กับ reinforement learning
Reward model คือมาดูว่าตอบดีหรือไม่ดี ข้อมูลที่เอามาเทรนคืออาจจะเป็นมนุษย์จัด rank ว่า คำตอบอันไหนดีสุด เช่น โมเดล Intruct GPT หรือไม่ก็อาจจะเป็นโมเดลเปรียบเทียบก็ได้ ว่าคำตอบอันไหนตอบดีกว่า เป็นแบบ preference pairs หลังจากนั้นก็เอามาเทรน reinforemence learning with human feedback (RLHF) คือหยิบเอา sample ใน dataset มาเป็น prompt แล้วพอได้คำตอบออกมา เอาคำตอบไปเข้า reward model วัดว่าคนชอบแค่ไหน ออกมาเป็นคะแนน ถ้าได้คะแนนสูง ก็เอามาอัปเดตโมเดลให้โมเดล generate เพิ่มขึ้น ถ้าคะแนนน้อยก็อัปเดตให้โมเดล generate น้อยลง
Reasoning Models
หรือ Thinking model คือ โมเดลที่ OpenAI เอา RL มา fine tune ต่อ ให้มันคิดก่อนตอบ สามารถไปดูเพิ่มเติมได้ที่นี่เลยนะ รูปข้างล่างเทียบระหว่าง LLMs แบบธรรมดา กับแบบที่เป็น Reasoning ก็ชัดเจนตามในรูปเลย
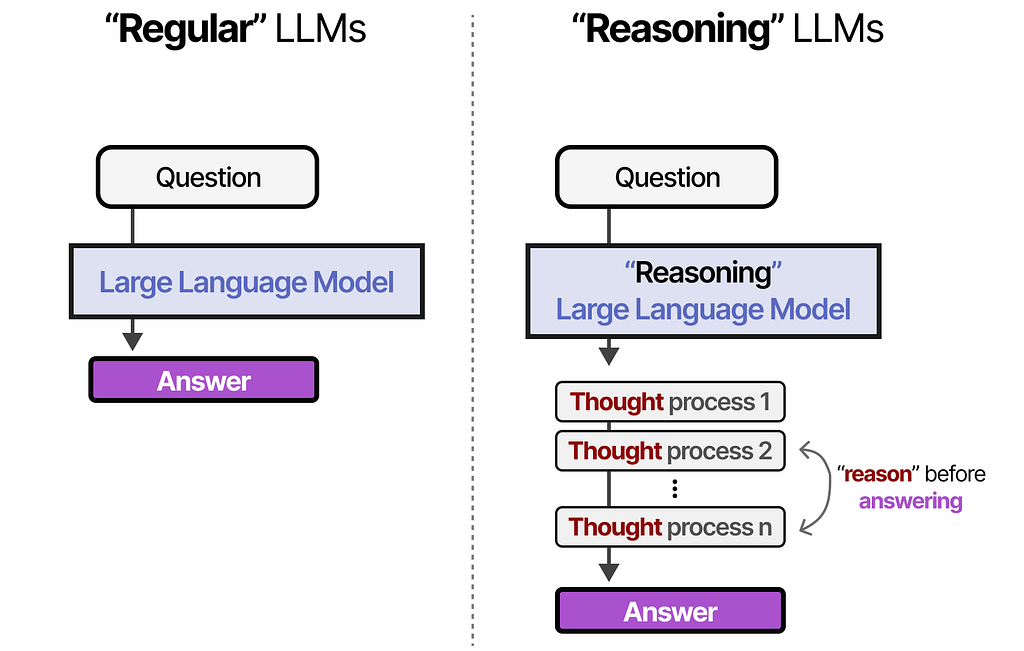
เบื้องหลังความสำเร็จของ LLMs
แล้วทำไม LLMs มันเก่งจัง จนหลายๆคนกลัวมันมาแย่งงาน
- ด้วยความที่มันถูกเทรนให้ predict คำต่อไป และมันได้เรียนรู้ word representation เปรียบเสมือนมันต้องเรียนรู้ world model โลกรู้ LLMs รู้
- นอกเหนือจากนั้นยังทำให้เรียนรู้แบบ multi task ได้
- Scaling Law — ข้อมูลที่เอามาเทรน ยิ่งเยอะยิ่งดี แต่ก็แพง ยิ่งเป็น reasoning LLMs นี่นึกพักใหญ่ กว่าจะตอบ
บทเรียนอันขมขื่น Bitter Lesson
AI Researcher มักจะยัดความคิดของคนเข้าไปในโมเดล เพื่อให้โมเดลมันฉลาดในสิ่งที่ researcher ต้องการ อันนี้จริงๆมันก็ดีนะ แต่ก็ดีใน short term
ใน long term จะเริ่มหิดปลาทูและ (hit the plateau) อารมณ์เหมือนออกกำลังกายตามโปรแกรมมานาน ซักพัก %fat เริ่มไม่ลงเว้ยเห้ย 5555 ต้องเปลี่ยนวิธีการลดใหม่ถ้าเป็นโมเดลก็เริ่มตันละ scale ไม่ได้
แต่ถ้าใช้ approach search and learning คือเหมือนให้ LLMs เป็นเด็กใฝ่รู้ใฝ่เรียนก็เพื่อให้มันสามารถ scale ได้ด้วยตัวมันเอง
EP.2 ขอพอแค่นี้ก่อน ช่วงนี้งานงอกเต็มไปหมด งานก็ต้องทำ ยิมก็ต้องเข้า ไม่เข้ายิมก็จะว้าวุ้นอีก ชีวิต 5555 เดี๋ยวครั้งหน้ามาต่อกันที่ Demo การต่อ API นะคะ ขอบพระคุณมากๆที่ติดตามค่า