LLM สมองบิน EP.3 — มาลอง Hands On เขียน Chatbot พร้อมอธิบายโค้ดละเอียดจัดๆ
ตอนนี้พอเข้าใจ concept ของ LLMs บ้างแล้วจากใน EP.1 และ EP.2 วันนี้จะมาลองเขียนโค้ดยิง API กันบ้างนะคะ
ในเลคเชอร์อาจารย์นัทแนะนำให้ใช้ OpenRouter นะ อารมณ์ตลาดรวมโมเดลต่างๆให้เลือกสรร ก่อนอื่นเลยสมัคร OpenRouter ก่อน แล้วไปสร้าง API key มา ส่วนเรายังไม่ได้สมัครเพราะเติมของ OpenAI ไว้แล้ว (ใครกลัวเปลือง จริงๆเติมไว้ซัก $5-$10 ก็ได้ ไม่น่าใช้เกินหรอก ยกเว้นเพื่อนเวรขโมยใช้ 555)
พอสมัครได้ API key มาแล้ว ปกติเราจะเก็บใน .env เพราะเผื่อเผลอ push code ขึ้น GitHub มันจะซวย 5555
วิธีการทำคือ ไปที่ terminal แล้ว cd ไป directory ของ project เรา
nano .env
แล้วให้เราใส่
OPENAI_API_KEY=“ใส่ API key ตรงนี้ โดยไม่ต้องใส่ quotation mark นะ”
ใครใช้ OpenRouter ก็ปรับเอาได้เลยค่ะ
ต่อไปเรามาเชื่อม API กัน
from openai import OpenAI
import os
load_dotenv(override=True)
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=api_key,
)
messages = [
{"role": "user",
"content": "Tell me a joke about cats."}
]
completion = client.chat.completions.create(
model="openai/gpt-4o",
messages=messages
)
print (completion.choices[0].message.content)
มาดูโครงสร้างของ messages กัน มันคือ list ของบทสนทนาระหว่าง user กับ assistant ซึ่งบทสนทนาจะเก็บเป็น dictionary
key จะมี “role” คือใครพูด กับ “content” คือใครพูดอะไร
ดูตัวอย่างกัน
messages = [
{"role": "user",
"content": "Hello!"},
{"role": "assistant",
"content" :"Hello, how can I help you?"},
{"role": "user",
"content" : "Can you help me write an email?"},
{"role": "assistant",
"content" : "Sure, what is it about?"}
]
บทสนทนาที่ยกตัวอย่างในเคสนี้คือเราจะต้องจัดการเอง เพราะ API ที่เราส่งไปมันไม่ได้จำบทสนทนา (Stateless Conversation) ถ้าเกิดจะให้บทสนทนามันตอบโต้ไปมา เวลาโมเดลมันตอบมา เราก็ต้องเอามาเก็บใน message ก่อน แล้ววนไปเรื่อยๆ
ตัวอย่าง code ของอาจารย์
msg_history = []
while True:
user_query = input('User: ')
msg_history.append({"role" : "user",
"content" : user_query})
response = client.chat.completions.create(
model = "gpt-4.1-mini"
message = msg_history
)
respoonse = response.choices[0].message.content
msg_history.append({"role" : "assistant",
"content" : response})
print("Assistant:" , response)
ก็คือสร้าง list ไว้เก็บ history ก่อน แล้วเอา response (choice ที่ 0) มา append ใส่ใน list ได้แล้ว chatbot ง่ายจัง 5555
ข้างบนมันแค่ตัวอย่างเฉยๆเพื่ออธิบายให้เก็ตนะ จริงๆควรเขียนเป็น function นะ จะเขียนยังไงก็ตามใจ ตราบใดที่กลับมาดู code ตัวเองแล้วไม่งง แต่เพื่อนงงมากกก
ตัวอย่างของเราจะประมาณนี้
def chat(message, history):
history = [{"role":h["role"],
"content":h["content"]} for h in history]
messages = [{"role": "system",
"content": system_message}
] + history + [
{"role": "user",
"content": message}]
response = openai.chat.completions.create(model=MODEL, messages=messages)
return response.choices[0].message.content
อธิบาย code สักนิด จิตแจ่มใส
def chat(message, history):
....
Function นี้เอาไว้ส่ง chat request ไปยัง OpenAI (หรือ OpenRouter) คือแทนที่มันจะถามคำตอบคำ จำอะไรก็ไม่ได้ เราก็จะเก็บ chat history ไว้ใน list ด้วย + กับ message ใหม่ของ user + กับ system message (เป็น instruction message เช่น You are a useful assistant หลายๆคนใช้ ChatGPT ก็จะมี prompt แบบนี้บ้าง ให้ตอบเฟรนด์ลี่ๆ หรือบางทีขอแบบดุดัน กวนตรีน ก็แล้วแต่ 555)
Parameter ที่รับจะเป็น message ใหม่ของ user กับ history ที่เป็น list เก็บบทสนทนาเก่า (หน้าตาเหมือนตัวอย่างโครงสร้าง message ข้างบนเลย)
history = [{"role":h["role"],
"content":h["content"]} for h in history]บรรทัดนี้เขียนเป็น list comprehension คือทุกๆ element h ใน list ที่ชื่อ history ให้สร้าง dictionary ที่มี key “role” กับ “content” พอมันมีบทสนทนาไปมาเยอะๆ มันก็จะมาวนลูปสร้าง list ในบรรทัดนี้
messages = [{"role": "system",
"content": system_message}
] + history + [
{"role": "user",
"content": message}]บรรทัดนี้จะสร้าง list message เริ่มด้วย system message (ประกาศไว้นอก function) + history ที่อธิบายไปตะกี้ แล้วก็ message ที่จะเข้ามาใหม่ ทีนี้มันก็จะเก็บ chat history และ
response = openai.chat.completions.create(model=MODEL, messages=messages)
บรรทัดนี้จะเรียก API และ ตรง MODEL ประกาศไว้นอก function หรือจะใส่ไว้ในนี้ก็ได้ ไม่มีไรมาก เหมือนตัวอย่างข้างบน เขียนเหมือนเดิม เป็น boiler plate code
return response.choices[0].message.content
บรรทัดนี้ให้ function return เป็น choice 0 เพราะปกติมันจะพ่นอะไรมามากมาย เราต้องการแค่ response message จากโมเดลเท่านั้น
ประมาณนี้ค่ะ น่าจะได้ chatbot แล้วนะ ฮูเลลลล!
Sampling Parameters
มีไว้คุมการ generate token (ในเลคเชอร์ อาจารย์บอกกันเงินไหลด้วย 5555) มีหลายอันเลย แต่หลักๆก็จะมี
Temperature เอาไว้คุมความกาว มีค่าระหว่าง 0–2 ยิ่งเยอะยิ่งกาว โคตรจะแรนด้อม จริงๆไม่ควรเกิน 1
ถ้าค่าเป็น 0 จะถามหัวใจกี่ครั้งก็ยังตอบเหมือนเดิม
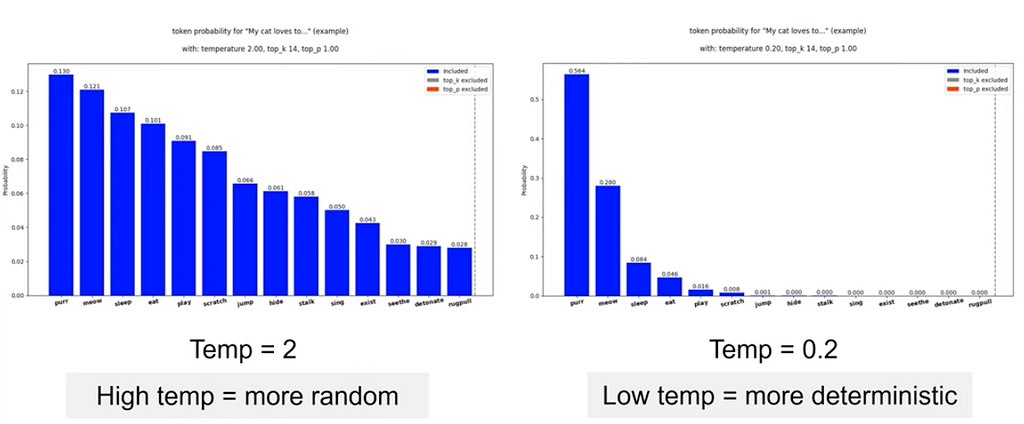
Top K (hard cut off sampler) จะเลือกเอาแค่ token ที่ probability ตัวท็อป
k=1 คือเอาท๊อป 1
k=100 เอาท๊อป 100
ถ้า k=0 ได้หมด ถ้าสดชื่น
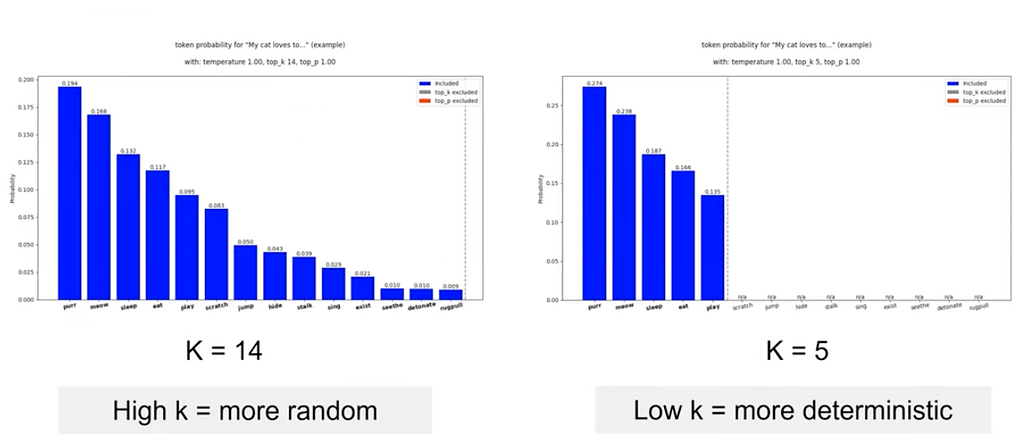
Top P (nucleus sampler) เอา token ที่ probability รวมกันได้ P ที่เลือก
P=1 เอาหมด
P=0.5 เอาเฉพาะ token ที่รวม prob กันได้ 0.5
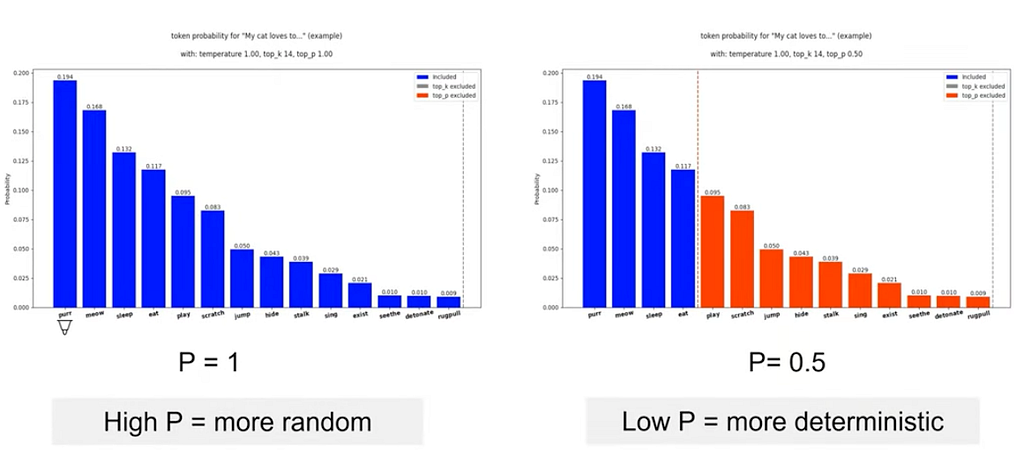
สำหรับ parameters ตัวอื่นๆ ดูได้ที่นี่เลยค่ะ จริงๆ in practice เราควรจัดการกับ prompt ก่อนเลย แล้วก็ temperature ด้วยก็ได้ขึ้นอยู่กับว่าอยากให้คำตอบสร้างสรรค์มากน้อยแค่ไหน แต่ละโมเดลก็จะมี recommendation ของค่า temp ไม่เหมือนกันด้วยนะ
เดี๋ยวครั้งหน้าจะมาเขียนเรื่อง Prompt Engineering บ้าง น่าจะได้อัปเดตถี่ขึ้น เพราะปรับตารางเวลาเข้ายิม จากสัปดาห์ละ 6 วัน เหลือ 5 วันพอ 5555 นักกายภาพเท้าสะเอวแล้ว
ขอบคุณทุกคนที่หลงเข้ามาอ่านนะคะ แล้วก็ขอบคุณ lecture อาจารย์นัทด้วย แบบดีมากจริงๆ คุณค่าที่คุณคู่ควร แนะนำให้ทุกคนที่สนใจด้านนี้ลองไปดูได้ค่ะ ความรู้ฟรีๆมีอยู่ทั่วไป แต่ความรู้ฟรีๆและดีด้วยทำให้รู้สึกว่าเหมือนเจอขุมทรัพย์ความรู้เลย เรานี่โชคดีจริงๆ
วันนี้ลาไปก่อน บั้ยบายยยค่าา