LLM สมองบิน EP.5 — Prompt Evaluations มาวัดกันไหม
สวัสดีค่าา กลับมาแล้ววว ยินดีต้อนรับสู่ซีรี่ส์ LLM สมองบิน ที่จะมาสรุปเลคเชอร์ของอาจารย์นัท ใน EP นี้เปิดมาก็จะวัดเลย 5555 ครั้งก่อนพูดถึง Prompt Engineering แบบเบสิคๆไปพอสังเขป คราวนี้จะขอวัดก่อน ถาม วัดอะไร ตอบ วัดกะกูป่ะล่าาาา (มุกนี้ยังมีใครเล่นอยู่ไหม 555)
Evaluations ของการทำ Prompt Engineering
ครั้งที่แล้วฉันพูดถึง Consumer prompts vs. Enterprise prompts ไปบ้างแล้ว ซึ่งในที่นี้เราจะโฟกัสกับ Enterprise prompts
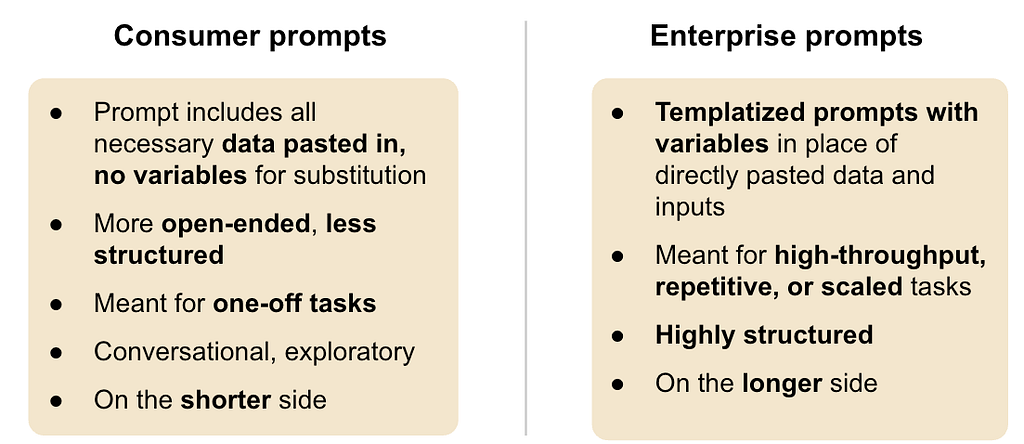
การทำ prompt ที่ดีต้องสามารถทดสอบ และปรับปรุงให้เก่งขึ้นได้ เริ่มจากทำ test case แล้วเอา prompt เอาไปทดสอบ แล้วดูว่า prompt ดีไหมด้วยขั้นตอนการ evaluation ทำเป็น back and fourth ไปเรื่อยๆจนมันเก่ง

มันจะอะไรกันหนักหนากับคำว่า all you need 55555

สรุปได้ว่าการวัดสำคัญมาก จะทำโปรเจค Generative AI อะไรมา อย่าลืมวัด!!! วัดอะไร ยังอีกก ยังไม่เลิกเล่น 55555
Evaluation ต่อไปนี้จะเรียกว่า Eval (อี-วาว 5555) คือ การวัด performance ของโมเดล LLM บน dataset ที่เราจัดให้มัน
แล้ววัดอะไรบ้าง?
- วัดกะกูป่ะล่ะ เห้ยย! ไม่ใช่ 5555 วัดความรู้ของโมเดลสำหรับ domain ที่เราสนใจ
- วัดความสามารถของโมเดลในการทำ task อะไรบางอย่าง
- วัด progress หรือ ความเปลี่ยนแปลง เวลาเปลี่ยนการ prompt แล้วดูการ generate ของโมเดล
วันนี้จะมาดู Prompt Evaluation แบบ deep ๆ กัน
ความแตกต่างระหว่าง Prompt Engineering กับ Prompt Eval คือ
- Prompt Engineering เราเขียนไปใน EP ที่แล้ว ก็คือเขียน prompt ให้ดีๆ แบบไหนคือดี ย้อนกลับไปอ่านแบบน้ำจิ้มใน EP.4 ได้เลยค่ะ (จริงๆมีลงรายละเอียดอีกอยู่ใน EP.7)
- Prompt Evaluation คือการทำ automate testing เพื่อวัดว่าโมเดลตอบดีแค่ไหนเทียบกับคำตอบที่เราคาดหวัง และเปรียบเทียบความเปลี่ยนของ prompt และสุดท้ายดูว่ามันพลาดตรงไหนจะได้ไปแก้ถูก
การ Eval prompt นั้นมี 3 รูปแบบ เรียงจากง่ายไปยาก
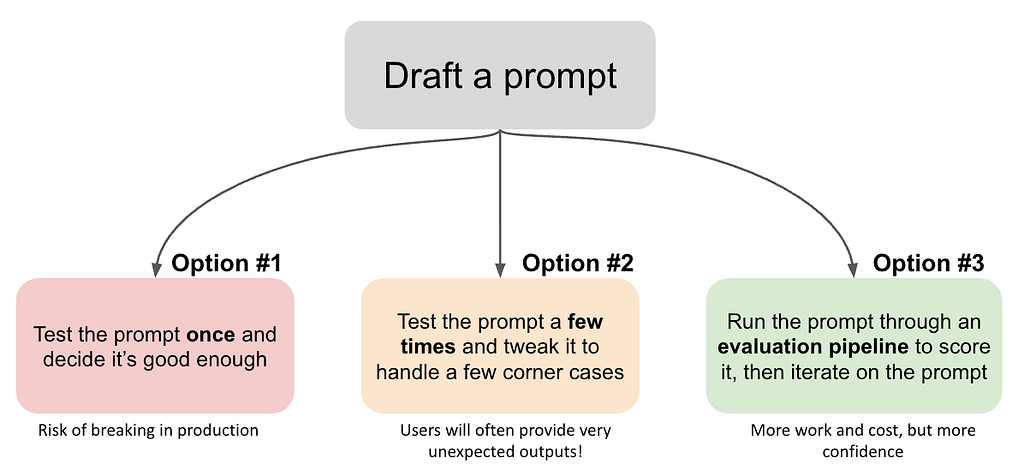
แบบง่าย #1 : ทดสอบครั้งเดียวก็เฟี้ยวได้ 555 แต่ก็เสี่ยงว่าจะเจ๊งตอนขึ้น production
แบบกลางๆ #2 : ทดสอบ >1 ครั้ง มีทดสอบ corner case ถ้า user ใส่ไรมาโบ้ๆเบ้ๆ แก้ได้ไหม แต่ก็อาจจะไม่ได้ดั่งใจ เพราะไม่ได้ทดสอบมากพอ
แบบสุดท้าย #3 : เล่นใหญ่สุดคือ เขียน eval pipeline เพื่อให้ score วัดว่ามันดีพอ
..พักหายใจลึกๆ 1 ที..
Eval Workflow มีหน้าตาประมาณรูปด้านล่างนี้
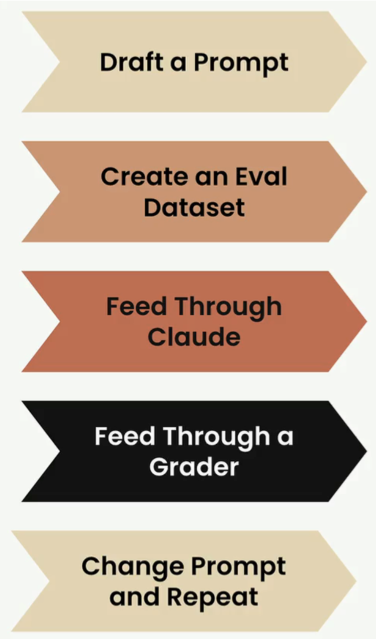
มาดูทีละอันกัน
- Draft a Prompt: เขียน prompt มาก่อน ดีไม่ดีไม่รู้แหละ มันจะรู้ตอน eval
prompt = f"""
Please answer the user's question:
{question}
"""
2. Create an Eval Dataset: สร้างชุดคำถามมา เพื่อเอามา merge กะ prompt เรา
3. Feed through Claude (หรือโมเดล LLM อื่นๆ): เอาไปเข้าโมเดล
4. Feed through a Grader: เอาคำตอบผ่าน grader ออกมาเป็นคะแนน
5. Change Prompt and Repeat: แก้ prompt แล้วทำใหม่ ดูว่าคะแนนดีขึ้นไหม
Types of Evaluations
แล้วประเภทของการ eval มีอะไรบ้าง มาดูกัน
- Choices คำถามแบบมีตัวเลือกคำตอบให้
- True or False: อันนี้ตรวจง่ายมาก เพราะคำตอบมีแค่ true หรือ false
- Multiple choices: คำถามช้อยส์ ตรวจง่ายเช่นกัน
2. Free Response คำถามแบบตอบเป็น text
- Keyword: คำถามปลายเปิด เริ่มตรวจยากและ ถ้าเจอ keyword ในคำตอบ ถือว่าผ่าน
- Short answer: ตรวจยาก ต้องเค้นสมองหน่อย 5555 ใช้มนุษย์ช่วยตรวจได้ rubric ต้องชัดเจน
- Essay: เหมือนกัน
- Comparison (A/B Testing): เปรียบเทียบคำตอบ แล้วให้มนุษย์เลือกว่าอันไหนตอบดีกว่า
มีคำถามแล้ว ไม่มีคนตรวจได้ไง มาดูกันว่า Graders หรือคนตรวจมีแบบไหนบ้าง
Graders มี 3 แบบ
- Code: ใช้โปรแกรมตรวจ พวกคำถาม choice ทำได้ เร็ว ประหยัด แต่คำถามปลายเปิดระดมสมองตรวจไม่ได้
- Model: ใช้โมเดล LLM-as-a-judge เป็นคนตรวจ ทำได้เร็ว ง่าย งานยากๆก็ได้ แต่ดูอีกทีว่าตรวจได้จริงไหม
- Human: ใช้คน แต่บาง domain ก็อาจจะหาคนยาก คิวฮอต ทำได้ช้า แพง
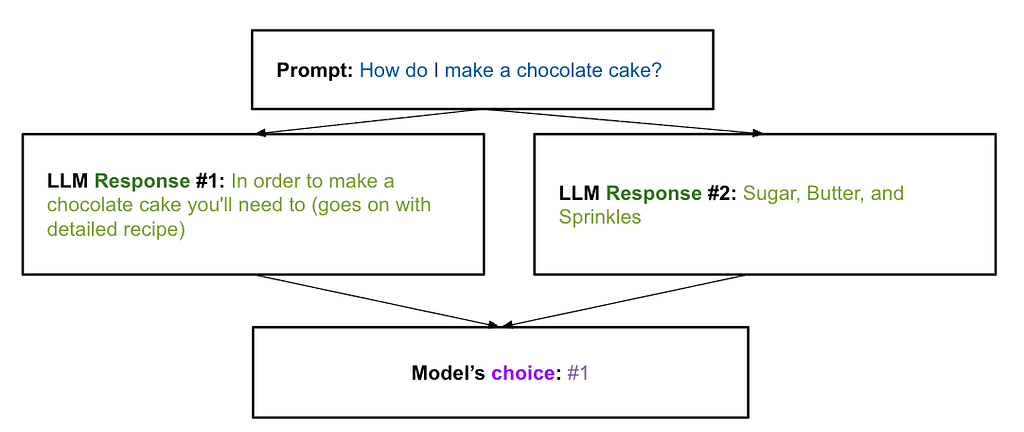
ยกตัวอย่างการใช้ LLM-as-a-judge แบบรูปข้างล่าง คือคำตอบออกมา 2 แบบ ก็ให้โมเดลเลือกว่าแบบไหนตอบดีกว่า
กับอีกตัวอย่างนึง มีคำตอบ กับ rubric ให้ว่าคำตอบแบบไหนถึงถือว่าเป็นคำตอบที่ดี แล้วก็ให้โมเดลตรวจตาม rubric
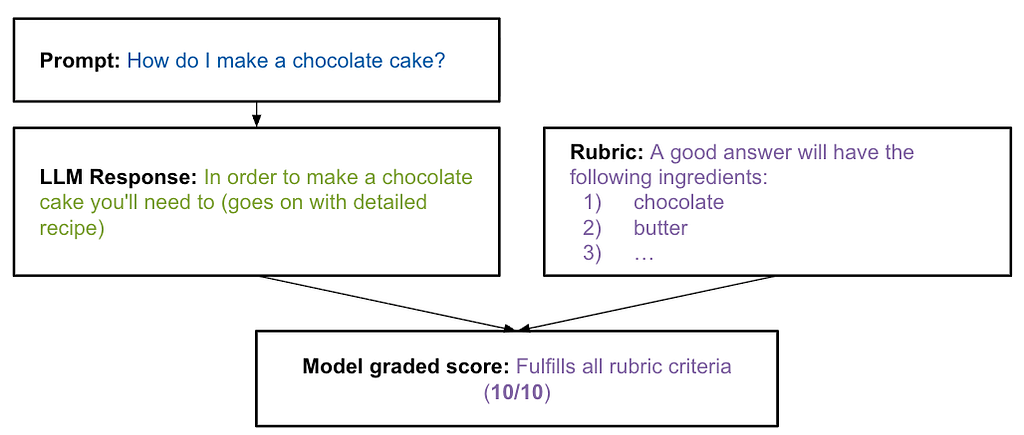
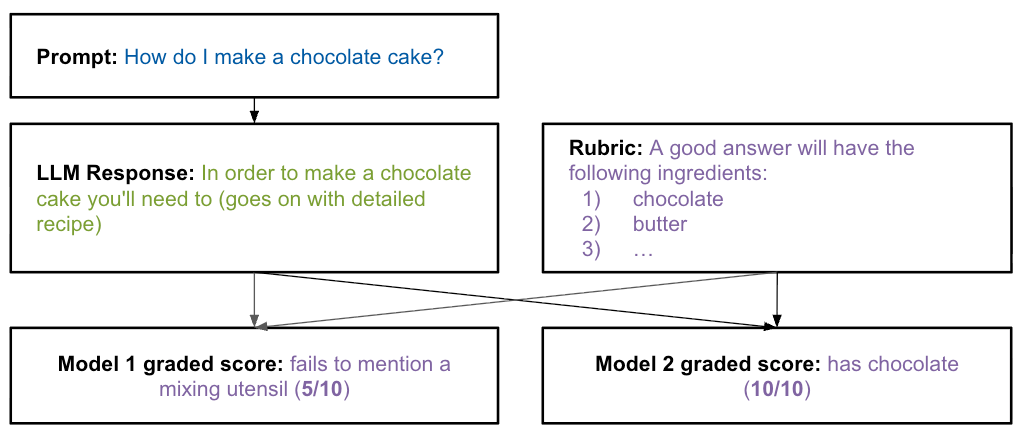
อันตะกี้มีโมเดลตรวจอันเดียว จริงๆใช้หลายตัวได้เหมือนกัน แบบตัวอย่างข้างล่างนี้ (ตอบมาคะแนนต่างกันครึ่งนึงเลย เวรกรรม 555)
การที่เราใช้ LLM-as-a-judge (LLM-based grading)ให้ปังนั้นก็จะมี best practice อยู่ดังนี้
- Rebric ต้องชัดเจน
- ต้องเฉพาะเจาะจงมากๆ ให้ตรวจว่าถูกหรือผิด แต่พวก scale 1–5 อาจจะต้องระวังความลำเอียง
- ให้โมเดลมี reasoning อธิบายว่า ทำไมถึง eval แบบนี้ ให้คิดก่อน
- เลือกใช้โมเดลดีๆ
ระวังเรื่อง Ordering Effect คือโมเดล bias เรื่องอันดับ เช่น ชอบตอบ A หรืออันดับที่มาก่อน
ต่อไปมาดูตัวอย่างการ prompt สำหรับ LLM-based grading
วิธีการ prompt ใช้ XML structure (ไอ้วงเล็บ <> </>) สำหรับแบ่ง part ดูตัวอย่างข้างล่างได้เลย
Grade this answer based on the rubric:
<rubric>{{rubric}}</rubric>
<question>{{question}}</question>
<answer>{{answer}}</answer>
Think through your reasoning in <thinking> tags, then output 'correct'
or 'incorrect' in <result> tags.""
แล้วเราจะเลือกใช้ grader อย่างไร
- ให้ task-specific ว่าเราจะทำอะไร คิดเผื่อ edge cases เช่น input โบ้ๆเบ้ๆ
- ถ้าเป็นไปได้ ให้ automate
- Volume > quality เน้นปริมาณ
สุดท้ายมาดู Evaluation Metrics ว่าวัดการ eval ด้วยอะไรได้บ้าง
- Word-Level Metrics (code grader): วัดแบบเทียบคำต่อคำ วัดด้วย BLEU, ROGUE, Perplexity, etc.
- Exact Match Metrics (code grader): วัดความแม่นยำ accuracy (correct / total) หรือใช้ confusion matrix ถ้า > 2 classes
ดู accuracy อย่างเดียวอาจจะไม่เวิร์คถ้า class มัน imbalance ก็ดู precision recall F1 - Task-Specific Rubrics (model or human): พวกคำถามปลายเปิด ต้องมี rubric ชัดเจน
S — Specific
M — Measurable
A — Achievable
R — Relevant
แล้ว Common Rubrics เราจะวัดด้วยเงื่อนไขอะไรได้บ้าง
- Task fidelity: โมเดลทำได้ดีแค่ไหน
- Consistency: โมเดลตอบเหมือนเดิมไหม
- Relevance and coherence: โมเดลตอบตรงคำถามใช่ไหม
- Tone and Style: ตอบตามสไตล์ที่ต้องการไหม
- Privacy preservation: โมเดลรักษาความลับได้ไหม
- Context Utilization: โมเดลเอาข้อมูลที่เราให้ไปใช้ไหม
- Latency: โมเดลตอบได้เร็วไหม
- Price: ราคา
เราสามารถใช้ LLM ช่วยคิดว่าจะให้ Rubric มีอะไรบ้าง
Common Mistakes
- Metrics ที่ใช้ต้องเกี่ยวกับ use case
- จริงๆ Latency กับ ความฉลาดของโมเดลก็ trade off กัน อาจจะต้องดีไซน์ UX เพื่อรองรับ latencyด้วย
Best Practices
- ต้องรู้ว่า user ซีเรียสเรื่องอะไร intelligent? latency? cost?
- ให้ความสำคัญทั้ง time กับ value
- ทำ UX ดีๆ เพื่อรองรับ latency
Challenges in Evaluation
- บาง domain อาจจะต้องใช้ domain expert
- บางงานทดสอบยาก
- ความยาวของบทสนทนาก็ทำให้ทดสอบยาก
- บางทีวัดยาก
- edge cases เช่น คำหยาบ
- เอาคนมา eval บางทีก็ subjective ใช้เวลานาน เปลืองตัง
- เอาโมเดลมา eval ก็ bias ความสามารถก็อาจจะจำกัด
จบแล้วสำหรับตอนวัดนี้ จริงๆเนื้อหายังมีอีก แต่ขอเขียนแยกออกไปอีก EP ดีกว่าเพราะยาวมากก น้ำตาจะไหล 55555 ขอบคุณเลคเชอร์อาจารย์นัทอีกครั้ง เป็นประโยชน์กับประชาชนคนไทยมากๆ
เดี๋ยวตอนหน้าจะมาเขียนสรุป Prompt Engineering with Evals กันนะคะ ช่วงนี้เขียนบ้างไม่เขียนบ้าง ติดซ้อม Hyrox 5555 ลงแข่งไว้ตอนมีนา บ้ามากก ยังไงก็ขอฝากไอจีฟิตหุ่นของเราหน่อยนะ อิอิ IG: @chaofitchick
ขอบคุณทุกคนที่หลงเข้ามาอ่าน ขอให้มีวันที่ดี สวัสดีค่าาาา