LLM สมองบิน EP.8 — ให้ RAG ช่วยค้นฟ้าคว้าดาว ไม่ต้องหยิบกาวมาดม (โคตรละเอียด)
สวัสดีค่าา วันนี้มาสรุป RAG กันนนนนน
อย่างที่อาจจะเคยบอกไปก่อนหน้านี้ว่า LLMs ถ้าไม่ prompt ดีๆ โมเดลมันก็ตอบได้ไม่ดีเช่นกัน ซึ่งความรู้ของ LLMs จะมาจาก training data แล้วก็ prompt ที่เราทำการ engineering มาอย่างดี แต่ context window มันก็จำกัด (คิดซะว่ามันคือความจำของโมเดล) prompt ดีแทบตาย สุดท้ายก็ลืม 555 แล้วก็บางทีโมเดลก็หลอนยา hallucinate ตอบอะไรไม่รู้แต่มั่นหน้ามั่นโหนกมาก ขอเบิ้ดกะโหลกซักที
ก็เลยมี RAG หรือ Retrieval Augmented Generation มาแก้ปัญหานี้ เพื่อให้โมเดลมีความรู้ในการตอบคำถามที่เราต้องการ ซึ่ง RAG แก้ปัญหาโดยการมี additional information หรือข้อมูลเพิ่มเติมให้กับโมเดล
สำหรับใครที่หลงเข้ามา สวัสดีนะคะ เราสรุปเนื้อหาจากเลคเชอร์ของอาจารย์นัทนะ เราเจอคลิปในยูทูปโดยบังเอิญ จดๆไว้แล้วเอามาเขียนสรุปก่อนจะลืม แล้วก็แอบมีเอามาต่อยอดเองด้วย เยี่ยมไปเลยยยย
ตัวอย่าง use case การใช้ RAG ก็จะเป็น Chatbot ที่เฉพาะเจาะจงกับธุรกิจนั้นๆ เช่น Chatbot ทางการแพทย์ (นี่เราเคยแอบกวนตีน บอกว่า ยาที่ใช้เป็นประจำคือ ยาสีฟัน 5555)
หน้าตาของ RAG ก็จะประมาณรูปด้านล่างนี้ รูปอันนี้เอามาจากคลิป RAG from scratch ที่เคยเรียนใน Youtube ใครสนใจตามไปดูได้เลยยย
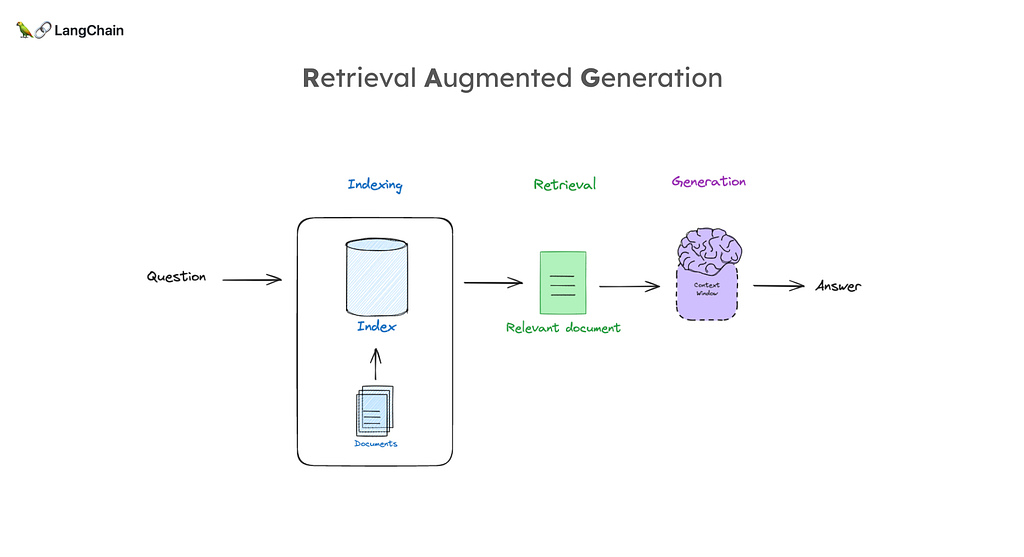
R — Retrieval
แบ่ง task ออกเป็น 3 ก้อนคือ
- Collection: คือการเก็บข้อมูล (Documents) ไว้ใน database ด้วยโมเดล embedding พูดถึงไปแล้วใน EP.2
- Organization: คือการจัดการข้อมูล เพื่อให้ค้นหาได้ เรียกว่า “Index”
- Search: คือค้นหา Index
A — Augmented
คือคำถาม user หรือ user’s query แทนที่จะตอบเลย มันจะวิ่งไปที่ knowledge base ด้วย เพื่อค้นหา docs ที่เกี่ยวข้อง มันคือขั้นตอน retrieval ที่บอกไปตะกี้
จากนั้นก็จะเอาสิ่งที่ได้จาก retrieval มารวมกับ prompt ของ user รวมกันเป็น โกโก้ครั้นนนชช เห้ยยย ไม่ใช่ 555 กลายเป็น augmented prompt
G — Generation
พอได้ augmented prompt แล้ว ก็เอาไปเข้าโมเดล LLM จากนั้นโมเดลก็จะ generate คำตอบออกมา แค่เนี้ยยยย
ซึ่งไอ้ RAG สามเกลอนี้ R — Retrieval จะมีความสำคัญมากที่สุด เพราะมันจะต้องไปหยิบข้อมูลที่สามารถเอามาตอบคำถามได้เป๊ะที่สุด มันจะทำได้ยังไง ไปดู
Information Retrieval
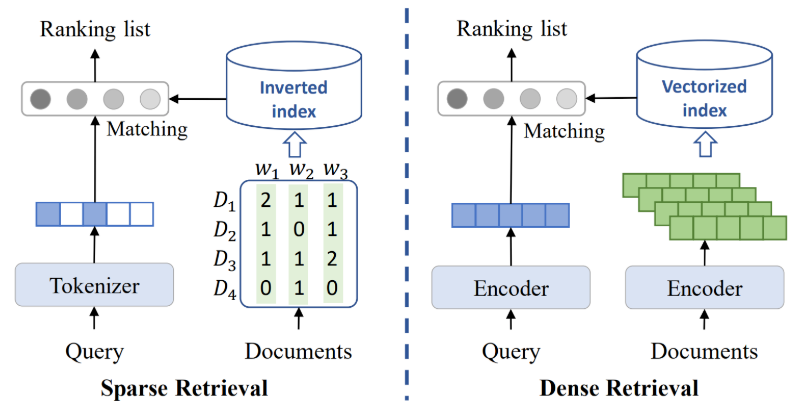
มี 2 แบบ
1. Sparse: Keyword Search
(อันนี้เราจะจำว่า มันหรอมแหรม มี 0 เยอะ ก็ได้ ได้ยินมาจากคลิปสอน NLP ของ อาจารย์เต้ อรรถพล นั่งดูอยู่ช่วงโควิด ว่างจัด 555)
- Keyword Matching: ชื่อก็ตรงตัวเลย ถ้าเจอ keyword ที่ตรงกัน ก็เอา value มาใส่ เหมือนเปิดพจนานุกรมหาความหมายของคำ เหมาะกับการใช้กับการ search หัวเรื่อง definition ของคำศัพท์ หรือ คำแปลกๆอย่าง วิงการ์เดียม เลวิโอซ่า ไรแบบนี้
database = {'ชวนีย์' : 'ผู้หญิงที่สวยมว้ากกก', 'ลิซ่า' : 'ผู้หญิงที่ร้องเพลงเก่งมาก'}
query = "ชวนีย์คือใคร"
augmented_query = "ชวนีย์คือใคร <context>ชวนีย์ = ผู้หญิงที่สวยมว้ากกก</context>"มาลองดู code กัน (ใน EP.3 เราเคยอธิบาย code เชื่อม API แบบทีละบรรทัดอยู่นะคะ ลองดูได้ค่ะ)
from openai import OpenAI
import os
load_dotenv(override=True)
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=api_key,
)
def generate(prompt):
response = client.chat.completions.create(
model="google/gemini-2.5-flash-lite,
messages = [{'role':'user',
'content':prompt}]
)
return response.choices[0].message.content
generate("Hello")
ต่อไปประกาศ keyword กัน ขอใช้เป็นชื่อเวทย์มนต์ใน Harry Potter นะ 555
knowledge_base = { 'เอกซ์เปกโต พาโตรนุม' : "คาถาผู้พิทักษ์ ใช้ปกป้องจากผู้คุมวิญญาณ.",
'วิงการ์เดียม เลวีโอซ่า' : 'ทำให้วัตถุลอยขึ้น',
'ลูมอส' : 'สร้างแสงสว่างที่ปลายไม้กายสิทธิ์',
'อาโลโฮโมร่า' : 'ใช้สะเดาะกลอนหรือเปิดประตู'
}เข้าสู่ช่วง RAG แว้วว ขออธิบาย codeใน comment เลยละกันนะ 555
def keyword_generate(query, docs):
# R -- Retrieval
"""
ทุกๆ key ที่อยู่ใน docs ถ้า key นั้นอยู่ใน query
ให้ดึง key และ value มา
แล้วขึ้นบรรทัดใหม่ วนลูปต่อไปเรื่อยๆ
"""
context = ''
for k in docs:
if k in query:
context += f'{k} = {docs[k]}\n'
# A -- Augmented Prompt
"""
เอาที่ retrieve มา เพิ่มกับ query
"""
prompt = f'''<question>{query}</question>
Please use context in tags to answer the question.
<context>{context}</context>'''
# G -- Generation
"""
generate prompt เรียก function ที่เขียนไว้ข้างบน
"""
response = generate(prompt)
print('Query:', query)
print('Retrieved documents:', context)
print('Response:', response)
query = 'อาโลโฮโมร่า คืออะไร?'
#call function ที่เขียนไว้ข้างบน
keyword_generate(query, knowledge_base)
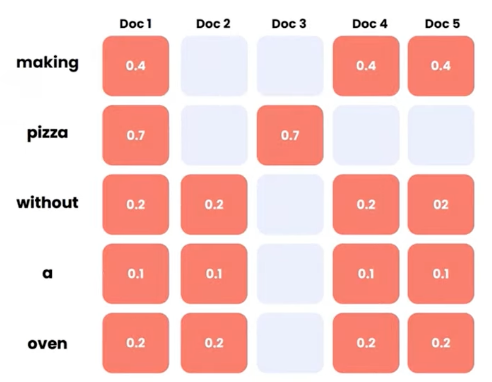
- Bag-of-words Search: คือเอาคำในประโยคมาตัดเป็นคำๆ ไม่สนใจลำดับคำ สนใจแค่ว่าคำนั้นมันมีในประโยคกี่รอบ แต่จริงๆแล้วบางคำใน query ก็ไม่ได้จะมีทุกคำใน documents ก็เลยเป็น sprase vector
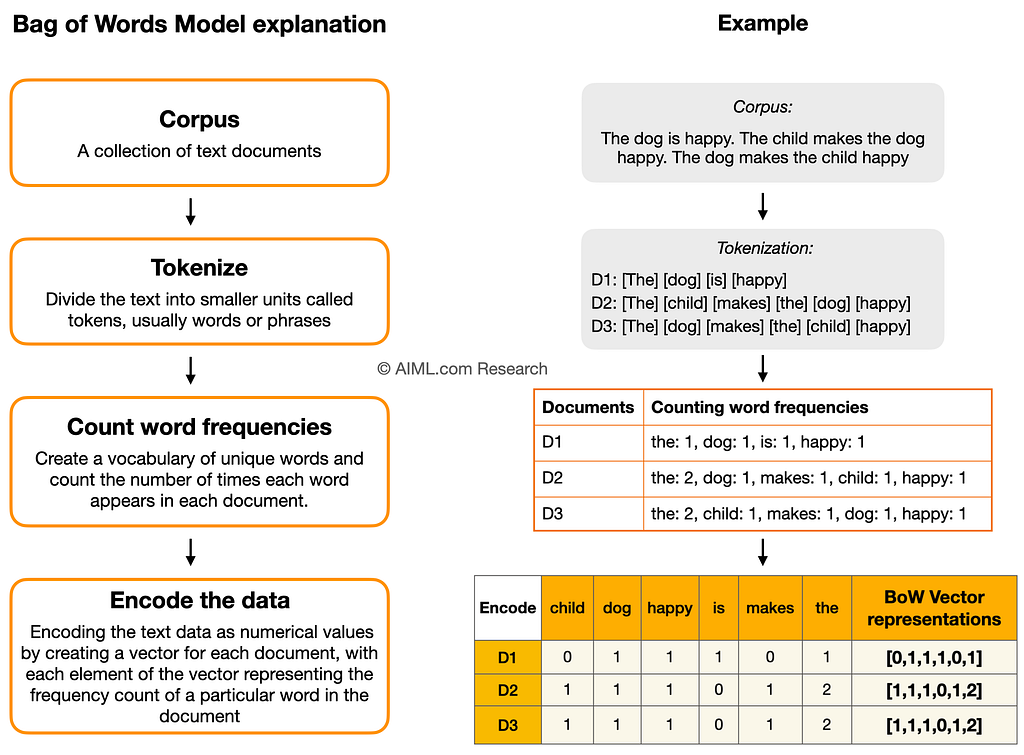
ตัวอย่างรูปข้างบน สมมติ corpus คือ user’s query
Bag-of-Words Search ก็จะเอาคำในประโยคมาเทียบกับแต่ละ documents ถ้าเจอก็ให้ 1 ไม่เจอก็ 0 จากนั้นก็ดูว่า document ไหนเจอคำมากที่สุด ก็ถือว่าเกี่ยวข้องกับ query มากที่สุดนั่นเอง
- Term Frequency-Inverse Document Frequency (TF-IDF): ถ้าดูจากแค่ความถี่ที่มีคำนั้นกี่คำ (Term Frequency) ก็อาจจะยังน้าาา เพราะบางคำที่มันเกิดขึ้นบ่อยๆ แบบ articles a an the หรือคำซ้ำๆ เยอะก็ไม่แฟร์ ก็เลยมี TF-IDF ในการให้ weight คำที่แรร์ๆ (เจอใน docs ไม่เยอะ) มากขึ้น
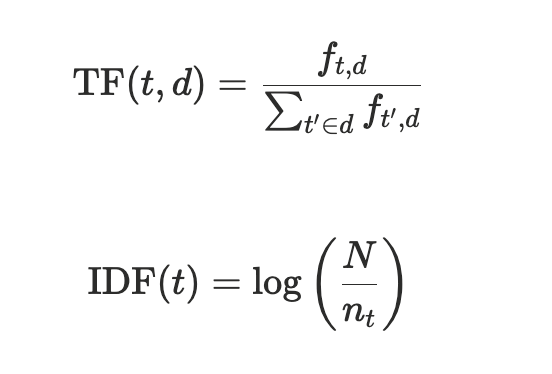
อธิบายก่อน
TF หาโดยการ เอาจำนวน docs ที่มีคำนั้น หารด้วย จำนวน docs ทั้งหมด แต่เราจะให้คะแนนคำหายากมากขึ้น ก็เลยหา IDF
IDF หาด้วยการ inverse ตามชื่อมันเลย ก็เอามาสลับบนล่าง จำนวน docs ทั้งหมด หารด้วย จำนวน docs ที่มีคำนั้น แล้วครอบด้วย log เพื่อ smooth ค่า
แล้วเอา TF กับ IDF มาคูณกัน
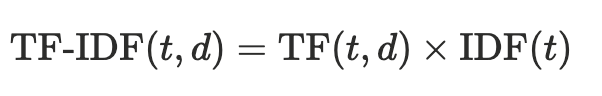
ยกตัวอย่างซักหน่อยค่ะ “Data science is fun because data drives decisions.”
ขั้นตอนที่ 1 นับเอกสารที่เจอคำ สมมติเอาคำว่า Data แล้วเจออยู่ 20 docs จากทั้งหมด 100 docs เพราะฉะนั้น TF = 0.2
ขั้นตอนที่ 2 เอามาสลับบนล่าง 100/20 = 5
ขั้นตอนที่ 3 take log(5) เพราะฉะนั้น IDF = 0.7
ขั้นตอนสุดท้ายย เอา TF x IDF = 0.2 * 0.7 = 0.14 แล้วก็เอาค่ามาใส่ใน vector ด้านล่างแบบในรูปตัวอย่างด้านล่าง ที่ไม่เกี่ยวกับตัวอย่างใดๆ 5555
pizza มี score สูงกว่าเพื่อน แสดงว่าคำนี้มันแรร์กว่าเพื่อน
- BM25 (Best Matching 25): ต่อมาก็มีคนเอา TF-IDF มาพัฒนาต่อเป็น BM25 สิ่งที่เพิ่มเติมมาคือมีการ normalize ความยาวเอกสารด้วย แล้วก็มี k กับ b เพิ่มมา (ถ้ามี a ด้วยจะเป็น akb เลย แต่ดีแล้วที่ไม่มี 555) BM25 สามารถหา score ของแต่ละคำ แต่ละ docs ได้
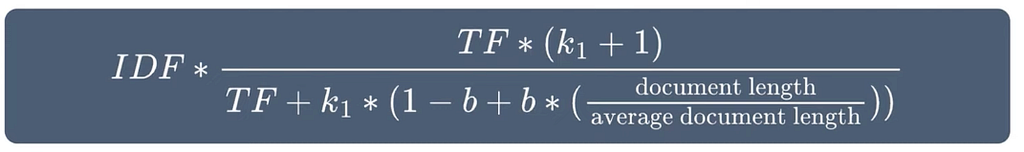
ความต่างของ BM25 กับ TF-IDF คือ
- สมมติว่า พบว่า Data ในเอกสาร 10 ครั้ง กับ 20 ครั้ง คะแนนมันจะคูณสองเลย มันดูเบิ้ล แต่ BM25 จะมีสุดอิ่มตัว (นึกถึงไขมัน 555) หรือ Term Frequency Saturation ด้วยการมี k กับ b เพิ่มมาเพื่อ weight ให้คะแนนน้อยลง 10 ไป 20 อาจจะไม่ต้องเบิ้ลคูณสอง อาจจะเหลือ 1.xx ไรแบบนี้
- TF-TDF เอกสารยาวๆจะโดนหารออก แต่ BM25 สามารถปรับให้ penalty น้อยลงได้
Parameters ของ BM25 ที่เอามา tune ได้ ที่บอกไปมี k กะ b
k คือไอ้ไขมัน Term Frequency Saturation เอาไว้ปรับว่าคำนั้นมีผลกระ score แค่ไหน อิ่มตัวที่จุดไหน เอา k เอาไปคูณกะ TF จะมีค่าระหว่าง 1.2 — 2.0 ซึ่ง ค่า k มาก TF มาก
b คือไอ้บี้ Length Normalisation ไว้ norm ความยาวว่าควรมีผลประมาณไหน docs มีค่าระหว่าง 0–1
เอาจริงป่ะ ถึงเวลาจริงๆ ไม่ได้จูน ก็ใช้ตาม default ของ lib อ่ะ 5555
มาดู code กัน (เอาของอาจารย์มาอธิบายนะ ไม่ได้เขียนเอง 5555)
!pip install rank_bm25
ลง package
from rank_bm25 import BM25Okapi
documents = [
"The quick brown fox jumps over the lazy dog",
"Machine learning helps computers learn from data",
"Natural language processing enables computers to understand human language",
"Foxes are wild animals found in forests and grasslands",
"Dogs are common household pets and loyal companions"
]
tokenized_docs = [doc.lower().split() for doc in documents]
bm25 = BM25Okapi(tokenized_docs)
Documents มีทั้งหมด 5 docs เอามา tokenize แบบ Bag-of-Words (ไม่สนใจลำดับคำ) แล้วก็เอา list ที่ tokenized แล้วตะกี้ มาใส่ใน object bm25
def BM25_retriever(query, top_k=2):
tokenized_query = query.lower().split()
doc_scores = bm25.get_scores(tokenized_query)
top_docs = sorted(enumerate(doc_scores), key=lambda x: x[1], reverse=True)[:top_k]
return [documents[i] for i, _ in top_docs]
ข้างบนเป็น function BM25_retriever รับ query กับ top_k (ที่พูดถึงข้างบนไปแล้ว เลือกความเหมาะสมตามจำนวนdocs ก็ได้)
อธิบายทีละบรรทัด:
tokenized_query = query.lower().split()
เอา query มาทำ Bag-of-Words
doc_scores = bm25.get_scores(tokenized_query)
หา score จาก object ที่ประกาศไว้ข้างบน จะได้ score ของแต่ละ docs
top_docs = sorted(enumerate(doc_scores), key=lambda x: x[1],
reverse=True)[:top_k]
เอา score ของแต่ละ docs มา sort ตาม top k โดยการ
enumerate(doc_scores)
enumerate คือ สร้าง list ของคู่ลำดับ docs กับ score ของแต่ละ docs
หน้าตาจะเป็นงี้ ยกตัวอย่างนะ [(0, 1.1), (1, 2.0), ….] ก็คือdocs ที่ 0 score=1.1 docs ที่ 1 score=2.0 ไปเรื่อยๆ
key=lambda x: x[1]
อันตะกี้ เราได้ [(0, 1.1), (1, 2.0), …] มาแล้ว จริงๆพิมพ์งี้จะดูง่ายกว่า
[(0, 1.1),
(1, 2.0),
……..]
เราต้องการให้ key เอามาแค่ score ซึ่งมันเก็บอยู่ใน x[1] ก็คือ 1.1, 2.0, …
(lambda เป็น anonymous function นิรนาม555 แทนที่เราจะเขียนแบบ def foo(x): … ก็จะยาวไป เขียนเป็น lambda เหลือบรรทัดเดียว)
sorted(enumerate(doc_scores), key=lambda x: x[1], reverse=True)[:top_k]
ครอบทั้งหมดนี้ด้วย sorted เพื่อ sort score ของแต่ละ docs จากมากไปน้อย แล้วเอาแค่ top k
return [documents[i] for i, _ in top_docs]
สุดท้ายก็ return ออกมาโดย เอา score จาก top_docs เมื่อกี้ เช่น [(1, 2.0), (0, 1.1)]
เอาวนลูป ทุกๆคู่ใน top docs เอา index ของ docs หรือ i มาเก็บใน list documents ส่วน score หรือแทนด้วย _ ไม่เอา ( _ แปลว่า มีแหละ แต่ไม่เอาโว๊ย 555)
ต่อไปได้เวลาของ RAG มีอธิบายไปแล้วก่อนหน้านี้ คิดว่าคงไม่ต้องแล้วค่ะ
def bm25_generate(query, top_k=3):
# R- Retrieval
retrieved_docs = BM25_retriever(query, top_k)
context = "\n".join(retrieved_docs)
# A-Augmented
prompt = f'''<question>{query}</question>
Please use context in tags to answr the question.
<centext>{context}</context>'''
# G-Generation
response = generate(prompt)
print('Query:', query)
print('Retrieved documents:', retrieved_docs)
print('\nResponse:', response)
query = "Can you tell me about machine learning?"
bm25_generate(query)
Sparse Search จบแล้ว เย้ ยาวมากกก 5555
2. Dense: Semantic Search
ที่ผ่านมา keyword search มันแค่ matching คำเฉยๆ ไม่ได้รู้เรื่องความหมายคำเลย ก็เลยต้องพึ่งพา embedding model เคยอธิบายไปแล้วใน EP.2 ลองไปดูได้เลยยย แต่อันนั้นเป็น word embedding จริงๆ embedding มันจะทำกับทั้งประโยคเลย หรือ documents ก็ได้เช่นกัน
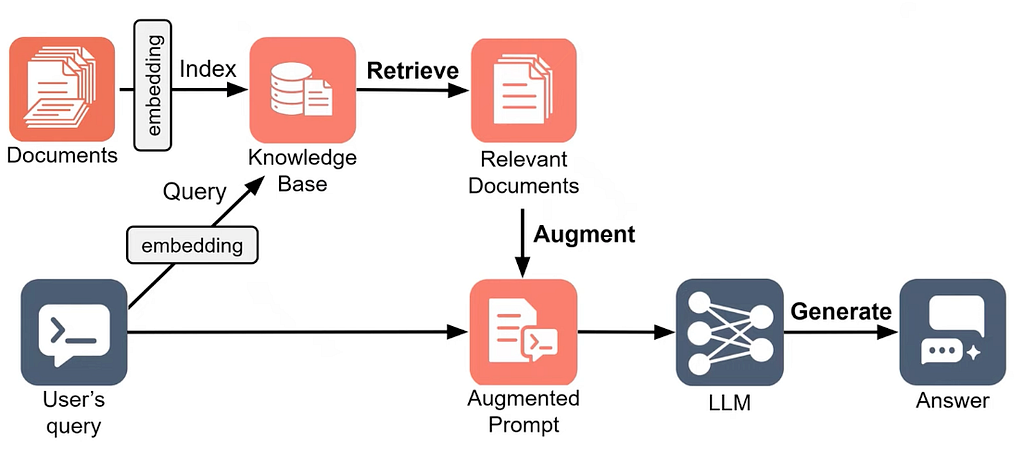
จากรูปข้างบนก็จะเอา documents (indexing) กับ user’s query (searching) ไปเข้าโมเดล embedding ก่อน ส่วน sparse search จะ tokenize เก็บเป็น Bag-of-Words ในขณะที่อันนี้ knowledge base จะเก็บเป็น vector database แล้ว
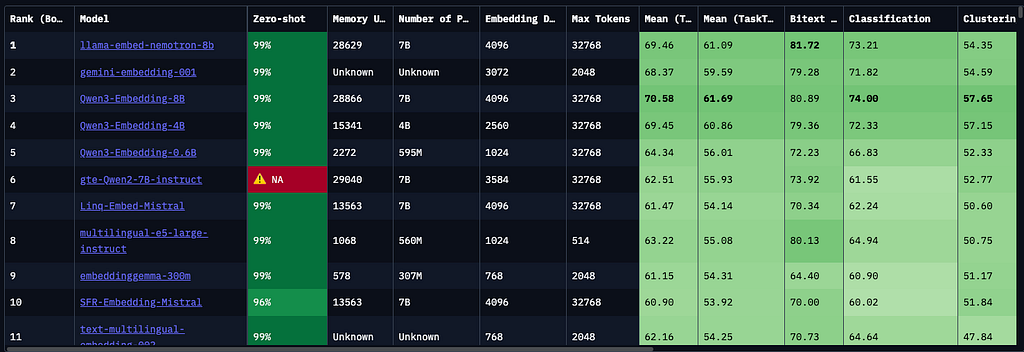
รูปข้างบนคือแผงโมเดล embedding ที่ HuggingFace จัดอันดับไว้ ดูที่ Number of Parameters กับ Embedding Dimension ยิ่งเยอะ แสดงว่าเก็บ semantic information ได้มาก
ตอน retrieve ก็จะเอา data chunk (จำนวนตามที่เราเลือก) จากผลลัพธ์ของ embedding ที่ใกล้เคียงกับ embedding ของ query มากที่สุด
มาดู code ต่อ
!pip install sentence_transformers datasets
ลง package ตัว embedding ของ HuggingFace
import torch
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
documents = [
"The quick brown fox jumps over the lazy dog",
"Machine learning helps computers learn from data",
"Natural language processing enables computers to understand human language",
"Foxes are wild animals found in forests and grasslands",
"Dogs are common household pets and loyal companions"
]
embed_model = SentenceTransformer('all-MiniLM-L6-v2')Instantiate โมเดล embedding
doc_embeddings = embed_model.encode(documents)
Embed (หรือ encode) documents
len(doc_embeddings[0])
เช็คดูความยาว จะเป็นตัวเลขมา หมายความว่ามี จำนวน x dimension ที่จะ represent ความหมายของคำ
def embedded_retriever(query, top_k=1):
# เอา query มาเข้าโมเดล embedding
query_embedded= embed_model.encode([query])
"""
หาความใกล้เคียงด้วย cosine similarity ระหว่าง query ที่ embed แล้ว
กับ docs ที่ embed แล้วตะกี้ข้างบน จะได้ออกมาเป็น array
"""
similarities = cosine_similarity(query_embedded, doc_embeddings)[0]
"""
เอา docs ที่เกี่ยวข้อง เฉพาะ top k โดยเอา array มา sort ก่อนจากน้อยไปมาก
[-top_k:] คือเอา index อันที่มีค่ามากที่สุด
[::-1] คือสลับอันดับ จากน้อยไปมาก เป็น มากไปน้อย
"""
top_indices = similarities.argsort()[-top_k:][::-1]
# return ออกมาเป็นทุกเอกสารที่อยู่ในตัวท็อป
return [documents[i] for i in top_indices]
Function ข้างบนคือเราจะ embed retrieval ก่อน อธิบายโค้ดใน comment นะคะ
def RAG_generate(query, top_k=3):
# R-Retrieval เรียก function embbed_retriever เมื่อตะกี้
retrieved_docs = embedded_retriever(query, top_k)
context = "\n".join(retrieved_docs)
# A-Augmented
prompt = f'''<question>{query}</question>
Please use context in tags to answr the question.
<context>{context}</context>'''
# G-Generation
response = generate(prompt)
print('Query:', query)
print('Retrieved documents:', retrieved_docs)
print('\nResponse:', response)
query = "Can you tell me about machine learning?"
RAG_generate(query)
RAG ก็เหมือนเดิมเลยย เพิ่มเติมคือจะเอา query มา embed ก่อน จบ อันนี้ถ้าเราไม่ได้ถามคำตอบงี้เป๊ะๆ แต่ความหมายใกล้เคียงกัน มันก็ยังหาเจอ จะต่างกับ Keyword Search ตรงนี้ค่ะ แต่ปัญหาก็คือ…
similarities = cosine_similarity(query_embedded, doc_embeddings)[0]
top_indices = similarities.argsort()[-top_k:][::-1]
ตอนหา cosine similarity แล้ว documents มี n docs runtime จะเป็น O(n) ลองจินตนาการว่าถ้ามี documents เยอะแบบวัวตายความล้ม ก็จะค่อนข้างใช้เวลาถ้าเรามานั่งเขียนเองท่านี้
จริงแล้วๆ เราสามารถใช้ vector database ได้ ที่จัดการให้เราได้เร็ว (อาจจะไม่จำเป็นในการใช้ทำ RAG ก็ได้ แต่ถ้าเริ่ม scale อาจจะต้องมีการเก็บที่เป็นกิจจะลักษณะขึ้น)
Vector DB มีหลายเจ้ามาก ส่วนตัวเราใช้ chroma เพราะมันเป็น opensource = ฟรี อิ__อิ ศรัทธาอันไหนก็ไปอ่าน docs ของเจ้านั้นได้เลยยย
Hybrid Search
ก็เป็นอีกทางนึงที่ทำทั้ง Keyword Search และ Semantic Search เลย แต่จะผลลัพธ์ของทั้งสอง search นี้จะมาจัดให้เป็น rank อันเดียวยังไงเนี่ยสิ
วิธีแรกคือ Reciprocal Rank Fusion: คือแปลง rank ให้เป็น score
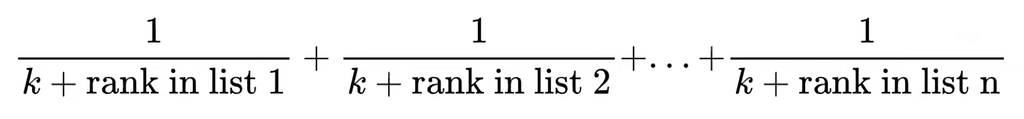
score เท่ากับ 1/rank เช่น อันดับ 1 = 1/1 score ก็จะเป็น 1
อันดับ 2 = 1/2 score ก็จะเป็น 0.5 จากนั้นเอามาบวกกัน
สามารถใส่ k เข้าไปได้ เพิ่มความแรง (ไม่ใช่สปริงนะ 555) ถ้า k มาก ความต่างของอันดับไม่มีผลไรมาก
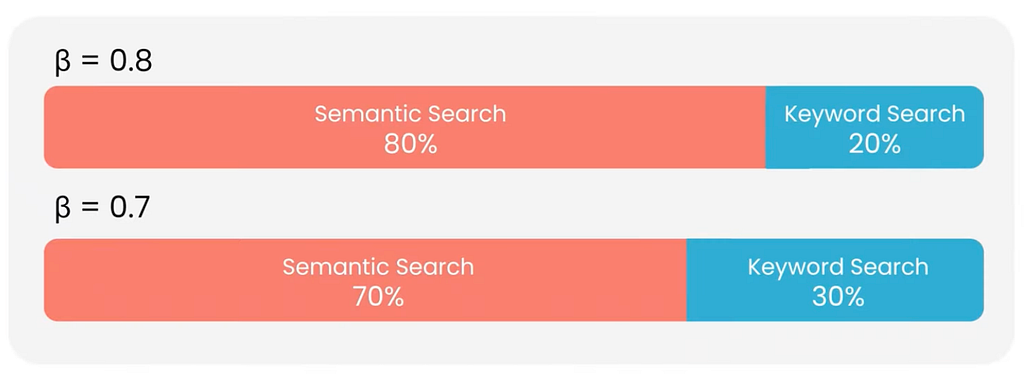
อีกวิธีคือ Beta Weighting:
Reranking
คือเทคนิคในส่วน retrieval คือจะมีอีกโมเดลมาแทรกก่อนจะเอาไปเข้าโมเดล LLM ซึ่งเทคนิคที่พูดถึงไปแล้ว (ที่ผ่าน embedding มาแล้ว) อาจจะไม่ได้ดีขนาดนั้น แต่มันก็ไวกว่าให้ไปค้น docs ใน knowledge base ทั้งหมด ถ้ามีหลายๆ docs เป็นหมื่นๆ
ซึ่ง reranking เหมือนจะมาช่วยเช็คอีกทีว่าที่ retrieve มามันเกี่ยวข้องกับ query จริงๆไหม แล้วจำมาจัดอันดับว่าอันไหนเกี่ยวสุด แล้วอาจจะมาเลือกมาแค่ top 5 ที่ดีที่สุดไปเข้า LLM
ข้อเสียของ reranking คือ แพงกว่าเทคนิคที่ใช้การหา cosine similarity
เจ้าที่ทำ reranking มี Cohere กับ Voyage AI ส่วนเราไม่เคยใช้อะ 5555 หรือใช้ LLM as a judge ได้ซึ่งเราก็ไม่เคยทำท่านี้เหมือนกัน
ตัวอย่าง code ดูได้ของอาจารย์เลย ขี้เกียจเขียนอธิบายแล้ว เพราะมันคล้ายๆกับที่อธิบายไว้ข้างบน แต่มา merge ตอนท้ายค่ะ ส่วน vector store ใช้ pinecone
นอกเหนือจากการ Retrieve ที่อาจจะเล่นใหญ่ไปหน่อยในบางกรณี มันก็มีอีกวิธีนึงคือการทำ Metadata Filtering ที่ทำได้ง่ายๆ ซึ่งก็คือการ filter อันที่ไม่เกี่ยวออกจากคำถาม เพื่อไม่ให้เสียเวลา search เช่น หัวเรื่อง ผู้เขียน วันที่ ฯลฯ
Filter อื่นๆก็มี Subscription Filtering, Geography Filtering ก็คือเอาบาง metadata ที่ไม่ต้องการออก
Chunking Strategies

รูปไม่เกี่ยวกับเนื้อหา แค่พูดคำว่า chunking แล้วนึกถึง chucky 5555
Chunking คือการตัดแบ่ง documents เป็นส่วนๆ ที่ต้องทำแบบนี้ เพราะถ้ายัด docs เข้าไปทั้งเล่มเข้าไปใน embedding มันจะอลังการงานสร้างขนาดไหน token เกิน
ถามว่าตัดแบบไหนดีล่ะ? จริงๆตัดเป็นหน้า เป็น paragraph เป็นประโยค ก็ได้ ขึ้นอยู่กับว่า
- Documents เข้ามาเป็นยังไง เป็นหนังสือแบบไหน มี chapter section อะไรไหม เลือกตามความเหมาะสม
- Embedding model ที่ใช้ แบ่งมากี่ token โมเดลถึงจะ optimized เช่น Sentence Transformer ก็จะมี prefer chunk แบบประโยค
- User’s query ว่าจะโบ้ๆเบ้ๆ แค่ไหน 5555 ถามสั้นๆ หรือถามอะไรยาวๆ ซับซ้อนๆ
- เอาไปใช้ยังไง semantic search? summary? ถ้าเอาไปเข้าโมเดล LLM ต่ออาจจะพิจารณา token limit ที่โมเดลนั้นรับได้ด้วย
Fixed Size Chunking
คือกำหนดเลยว่า chunk นึง จะตัดกี่ตัว แต่อาจจะตัดมาไม่เต็มประโยค (fragment) ก็อาจจะกำหนดให้ overlap ได้ มีเหลื่อมๆมาด้วยได้
ใช้ library ได้ code ตัวอย่างด้านล่างใช้ Langchain ตัดออกมาซื่อๆเลย ไม่ได้ดูความหมายอะไรทั้งสิ้นนะ
text = "..."
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
Sentence Splitting
คือการตัดตามประโยค ใช้ library NLP ต่างๆมาช่วยตัดได้ ซึ่ง logic ง่ายๆในการตัดประโยคก็คือ full stop ในประโยค หรือ question mark อะไรแบบนี้ ซึ่งใช้กับภาษาไทยอาจจะไม่เหมาะ เพราะภาษาไทยเป็นภาษาที่บรรยายแบบฉ่ำ 5555 คนไทยไปเรื่อยคือเรื่องจริง
ตัวอย่าง code
text = "..."
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpacyTextSplitter()
docs = text_splitter.split_text(text)
Recursive Chunking
เห็นคำว่า recursive ก็อาจจะนึกถึงการเขียนโค้ดแบบ recursive function ที่เรียกตัวมันเองเนอะ เพื่อลด complexity ของโปรแกรม anyway ในที่นี้เรากำหนด chunk size ไว้ แล้วถ้าตอนตัดมันตัดมาโบ้ๆเบ้ๆ ก็จะลด chunk size ลงไปเรื่อยๆจนกว่าที่ตัดมาจะได้ structure ที่โอเค
ตัวอย่าง code
text = "..."
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 256,
chunk_overlap = 20
)
Specialized Chunking
คือ ตัดตาม Markdown (แบ่งตาม header # ## ###) ตัดตาม Latex ตัดตาม HTML (<h1>…</h1> ตัดตาม function Python (def foo(): …)
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = "..."
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
Semantic Chunking
คือตัดตามความหมาย ให้แต่ละ chunk มีความหมายใกล้เคียงกัน

แล้วตัดยังไง?
แบ่ง docs เป็นประโยคก่อน แล้วจัดการแปลงเป็น vector แล้วเทียบระหว่างประโยคด้วยการหา distance (cosine similarity) ถ้าค่า distance ออกมาต่ำกว่า threshold ก็ทำการเพิ่มประโยคเข้าไปใน chunk ถ้าเกิน threshold ก็หยุด ไปดู chunk ใหม่
ถ้าอยากอ่านเพิ่มเติมเราแนะนำอ่านอันนี้ค่ะ
Language Based Chunking
เอา LLM มาใช้ให้เกิดประโยชน์ 5555 คือเรา prompt LLM ให้มันตัดให้ ใช้เงินแก้ปัญหา
หลังจากทำ chunking เสร็จ ยังไม่จบเท่านี้ ก็ยังมีปัญหาอยู่ บางทีตัดแล้ว information บางอย่างหาย อย่างเช่น อีกประโยค ประธานอาจจะเป็น pronoun (He, she ,it) ซึ่งเราก็ไม่รู้ว่าหมายถึงใคร เราจะรู้ก็ต่อเมื่อเราเห็นประโยคก่อนหน้าอีก chunk นึง บางทีอารัมภบทเยอะ อยู่ซะไกลเลย 5555 ความไม่รู้นี้ก็มีผลกับการตอบคำถามของโมเดลเหมือนกัน
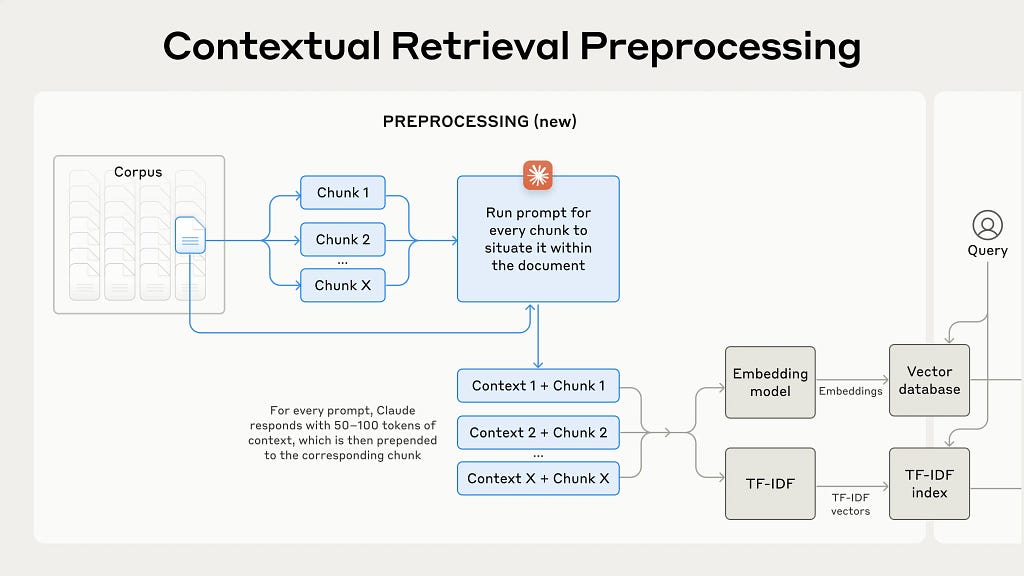
ก็เลยมี Contextual Retrieval มาเติม chunk เดิม ให้มีข้อมูลเพิ่ม

วิธีการทำคือ ใช้โมเดล LLM ทำ ด้วยการ prompt
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within
the overall document for the purposes of improving search retrieval
of the chunk. Answer only with the succinct context and nothing else.
เทียบระหว่าง RAG ท่าปกติ
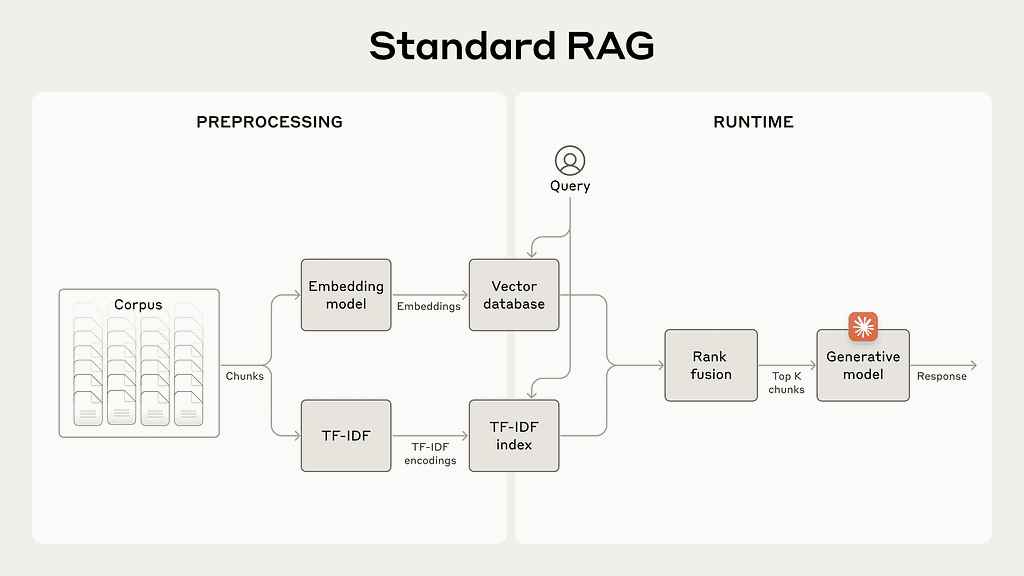
กับ RAG ที่ใช้เทคนิค contextual retrieval ก่อนเข้าโมเดล embedding
Query Rewriting
คือการเอาคำถามมาแต่งใหม่ เพราะบางที user ถามhaอะไรก็ไม่รู้ 555 ซึ่ง embedding model ก็ไม่ได้ฉลาดขนาดนั้น เราอาจจะต้องช่วยมันด้วย
วิธีทำ ใช้ LLM ทำ เช่นอาจจะ prompt ว่า ให้เขียนใหม่ เป็นภาษาทางการมากขึ้น ตัดที่ไม่เกี่ยวออก paraphase เพื่อให้มีโอกาสค้น documents เจอ อะไรแบบนี้
- Multi-Query คือการ prompt ให้โมเดล generate คำถามออกมาหลายๆเวอร์ชั่น
- HyDE: Hypothetical Document Embeddings คือการแปลงคำถามเป็น documents โดย prompt ให้ LLM แปลงคำถามพวก wh questions(What, when, …) สร้าง hypothetical docs
RAG Evaluations
ได้เวลาวัดแล้ว 5555
สิ่งที่จะวัดได้คือ docs ที่ออกมาจาก retrieval เกี่ยวข้องแค่ไหน จำเป็นไหม หรือ ออกทะเล กับ คำตอบตอบตรงคำถามไหม
RAG แบ่งออกเป็น 3 ส่วนคือ Question (Q) Retrieved Context (C) Answer (A)
- Context Relevance (C|Q) คือวัดว่าที่ retrieval ตรงกับคำถามไหม
Metrics ในการวัดคือ คำถาม คำตอบของโมเดล และเฉลย(อาจจะต้องใช้ domain expert)

- Recall: หาว่าข้อมูลที่จะต้องดึงมา เอามาครบเท่าไหร่
หาโดยการ เอาข้อมูลที่ดึงมา หารด้วย ข้อมูลที่จะต้องดึงมาทั้งหมด
(Relevant Retrieved / Total Relevant) - Precision: หาว่าข้อมูลที่ดึงมาทั้งหมด ที่มันเกี่ยวข้องจริงๆมีเท่าไหร่
หาโดยการ เอาข้อมูลที่ดึงมา หารด้วย ข้อมูลที่ดึงมาทั้งหมด
(Relevant Retrieved / Total Retrieved)
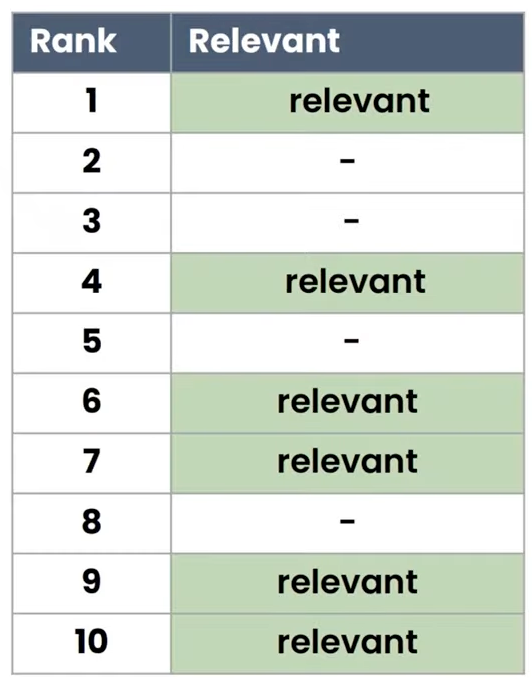
ตัวอย่าง สมมติว่าอันนี้เป็น top k docs ที่ดึงมา k =10
Precision @ 5 = 2/5 = 40%
Precision @ 10 = 6/10 = 60%
Recall ติ้งต่างว่าที่เกี่ยวข้องมีทั้งหมด Total Relevant = 8
Recall @ 10 = 6/8 = 75%
ในกรณีที่ไม่มีเฉลย (ground truth) อาจจะใช้ LLM ช่วยสร้างคำถาม โดย sample chunk มาจาก knowledge base แล้วเอาคำถามมาเช็คด้วย LLM อีกตัว (LLM-as-a-judge) ว่าคำถามดีไหม เช็คว่า คำถามเอามาจาก context จริงๆ กับ คำถามเป็นไปตามที่เราต้องการ และ คำถามนั้นใช้ context มาตอบพอไหม หรือต้องใช้ context นอกเหนือจากนี้ด้วย
2. Faithfulness/Groundedness (A|C) คือวัดว่าโมเดลตอบคำถามจาก context ที่ดึงมาไหม ตอบเกินเบอร์ไหม หรือไม่เกินไม่ขาดพอดีเป๊ะ

3. Answer Relevance (A|Q) คือวัดว่าตอบตรงคำถามไหม

Advanced RAG Relationships
4. Context Support Coverage (C|A) คือ context ที่ดึงมาตอบคำถามได้ไหม พอไหม
5. Question Answerability (Q|C) คือ context ที่ให้มาดึงมาครบไหม
6. Self-Containment (Q|A) คือ ข้อมูลที่มีเอามาตอบคำถามได้จริงไหม
สิ่งอื่นๆที่ต้องพิจารณาคือ Latency และ Cost
จบบแล้วววกับ RAG สมองบวม ตอนนี้นานนิดนึง ใช้เวลาเขียนพอสมควรอยู่ 5555 หวังว่าจะไม่งงนะคะ วันนี้ขอลาไปก่อน พบกันใหม่ในตอนหน้านะคะ
ขอบคุณที่ติดตามค่าา ฝาก IG: @chaofitchick ไปตามดูเราออกกำลังกายซ้อมแข่ง Hyrox ได้ ทุกกำลังใจมีความหมายมากๆค่า